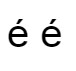| JavaScript Canvas - Unicode |
| Written by Ian Elliot | |||
| Monday, 04 January 2021 | |||
Page 2 of 2
UTF-16 in JavaScriptNow we come to a confusing twist in the story. JavaScript has Unicode support and all JavaScript strings are UTF-16 coded – this has some unexpected results for any programmer under the impression that they can assume that one character is one byte. While you can mostly ignore the encoding used, the fact that web pages and script files use UTF-8 and JavaScript uses UTF-16 can cause problems. The important point to note is that when JavaScript interacts with a web page characters are converted from UTF-8 to UTF-16 and vice versa. As you can guess, UTF-16 is another variable length way of coding Unicode, but as the basic unit is 16 bits we only need to allow for the possibility of an additional two-byte word. For any Unicode character in the range U+0000 to U+FFFF, i.e. 16 bits, you simply set the single 16-bit word to the code. So how do we detect that two 16-bit words, called a surrogate pair, are needed? The answer is that the range U+D800 to U+DFFF is reserved and doesn't represent any valid character, i.e. they never occur in a valid string. These reserved codes are used to signal a two-word coding. If you have a Unicode character that has a code larger than U+FFFF then you have to convert it into a surrogate pair using the following steps:
Reconstructing the character code is just the same process in reverse. If you find a 16-bit value in the range x0800 to xDFFF then it and the next 16‑bit value are a surrogate pair. Take 0xD800 from the first and 0xDC00 from the second. Put the two together to make a 20-bit value and add 0x0100000. The only problem is that different machines use different byte orderings - little endian and big endian. To tell which sort of machine you are working with, a Byte Order mark or BOM can be included in a string U+FEFF. If this is read as FFEF the machine doing the decoding has a different byte order to the machine that did the coding. The most important thing to know is that JavaScript only uses a single 16-bit value to represent a character. This means it doesn't naturally work with the full range of Unicode characters as there are no surrogate pairs. The BMP - Basic Multilingual PlaneA JavaScript string usually uses nothing but characters that can be represented in a single 16-bit word in UTF-16. As long as you can restrict yourself to the Basic Multilingual Plane (BMP), as this set is referred to, everything works simply. If you can't, then things become much harder. You can enter a Unicode character using an escape sequence: \xHH for characters that have codes up to xFF, i.e. 0 to 255, and: \uHHHH for characters that have codes up to xFFFF, where H is a hex digit. For example: var a = "Hello World\u00A9"; adds a copyright symbol to the end of Hello World. This is simple enough, but if you now try: console.log(a.length); you will find that it correctly displays 12, because the length property counts the number of 16-bit characters in a string. What about the Unicode characters that need two bytes? How can you enter them? The answer is that in ECMAScript 2015 and later you can enter a 32-bit character code: \u{HHHHHHHH}
Alternatively you could use the new string functions also introduced in ECMAScript 2015, fromCharCode and fromCodePoint do the same job of converting a character code to a string. However, fromCharCode only works with 16-bit values and not surrogate pairs, while fromCodePoint will return a surrogate pair if the code is greater then 0xFFFF. The only problem is that fromCodePoint was introduced with ECMAScript 2015 and isn't supported in older browsers, although a polyfill is available. The functions charCodeAt and codePointAt will return the character code at a specified position in a string. The charCodeAt function, which also isn’t supported by older browsers, works in 16-bit values and is blind to surrogate pairs, whereas codePointAt will return a value greater than 0xFFFF if the position is the start of a surrogate pair. Notice, however, that the position is still in terms of 16-bit values and not characters. For example: var s1="\u{1F638}"; or: var s1=String.fromCodePoint(0x1F638); stores the surrogate pair \uD83D\uDE38 in s1 which is the "grinning cat face with smiling eyes" emoji:
If you cannot assume ECMAScript 2015 then you have to enter the surrogate pair as two characters. You can easily write a function that will return a UTF-16 encoding of a Unicode character code: function codeToUTF16(code) {
if (code <= 0xFFFF) return "\\u" +
For example: console.log(codeToUTF16(0x1F638)); produces: \uD83D\uDE38 which is the "grinning cat face with smiling eyes" again. Notice JavaScript sends the UTF-16 to the browser unmodified – it is the browser that converts it to equivalent UTF-8 and then displays it. JavaScript ProblemsAs long as you restrict yourself to the BMP everything works an a fairly simple way. If you move outside of the BMP to make use of emojis say then things are more complicated. Most of the JavaScript functions only work when you use characters from the BMP and there is a one-to-one correspondence between 16-bit values and characters. JavaScript may display surrogate pairs correctly, but in general it doesn't process them correctly. For example, length gives you the wrong number of characters if there are surrogate pairs. Functions like charAt(n) will return the wrong character if n is beyond a surrogate pair and it might not even return a valid character if it selects the second value of the pair. In general, you just have to think that all JavaScript functions work with 16-bit characters and if you use a surrogate pair then these are treated as two characters and one of these might even be invalid. There is one final problem that you need to be aware of. In Unicode a single code always produces the same glyph or character, but there may be many characters that look identical. In technical terms, you can create the same glyph in different ways. Unicode supports combining codes which put together multiple characters into a single character. This means that you can often obtain a character with an accent either by selecting a character with an accent or selecting a character without an accent and combining it with the appropriate accent character. The end result is that two Unicode strings can look identical and yet be represented by different codes. This means the two strings won't be treated as being equal and they might not even have the same length. The solution to this problem is to normalize the strings so that characters are always produced in the same way. This is not an easy topic to deal with in general as there are so many possible ways of approaching it. For example there are two ways of specifying an accented e: var s1 = '\u00E9'; var s2 = 'e\u0301'; ctx.font="normal normal 40px arial"; ctx.fillText(s1+" "+s2,10,60); both of which produce apparently the same character:
ECMA 2015 introduced the normalize method and: s1.normalize() ===s2.normalize(); is true and both are equal to \u00E9. You can also specify the particular type of normalization you require, but this is beyond the scope of this introduction to working with Unicode text. Related ArticlesReading A BMP File In JavaScript Getting Started with Box2D in JavaScript Summary
Now available as a paperback or ebook from Amazon.JavaScript Bitmap Graphics
|
|||
| Last Updated ( Monday, 04 January 2021 ) |