| OpenAI o1 Thinks Before It Answers |
| Written by Sue Gee | |||
| Friday, 13 September 2024 | |||
|
OpenAI has unveiled a new series of AI models that can reason through complex task and solve hard problems. The first fruit of OpenAI's "Strawberry Project", o1-preview is now available in ChatGPT and the OpenAI API and will be included in ChatGPT Enterprise and Edu next week.
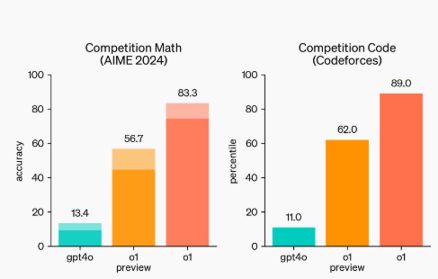
If you've been impressed by the lightening speed with which ChatGPT and other LLMs provide answers, you might be disappointed to discover that o1 is comparatively slow. This is deliberate. The distinguishing feature of the new series of AI models is that they have been designed to spend more time thinking before they respond, using a "chain-of-thought" approach. We've reported a year ago on research from Google Deepmind that suggested that prompting a ChatBot to pause to think and to take a step-by-step approach results in more accurate results and, working on its highly secretive "Project Strawberry" OpenAI has put this into practice. According to OpenAI: Similar to how a human may think for a long time before responding to a difficult question, o1 uses a chain of thought when attempting to solve a problem. Through reinforcement learning, o1 learns to hone its chain of thought and refine the strategies it uses. It learns to recognize and correct its mistakes. It learns to break down tricky steps into simpler ones. It learns to try a different approach when the current one isn’t working. This process dramatically improves the model’s ability to reason. OpenAI has provided some impressive results that demonstrate the success of the new approach. These charts compare GPT-4o abilities in comparison to o1-preview and o1 at Competition Math and Coding: A new Competition Math benchmark was selected on the grounds that "recent frontier models", referring to Anthropic's Claude and Google's Gemini, do so well on the MATH and GSM8K benchmarks previously used are no longer effective at differentiating models. The substitute benchmark is AIME, described as an exam designed to challenge the brightest high school math students in America and it certainly differentiates between GTP-4's approach and that of the o1 series. While GPT-4 only solved on average 1.8 out of 15 problems, o1 solved 11.1 problems with a single sample per problem, 12.5 (83%) with consensus among 64 samples, and 13.9 (93%) when re-ranking 1000 samples with a learned scoring function. A score of 13.9 places it among the top 500 students nationally and above the cutoff for the USA Mathematical Olympiad.
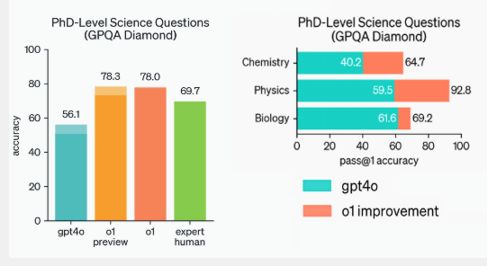
OpenAI also evaluated o1 on GPQA diamond which tests for expertise in chemistry, physics and biology. In order to compare models to humans, experts with PhDs were recruited to answer GPQA-diamond questions. o1 surpassed the performance of the human experts, becoming the first model to do so on this benchmark. Another important respect in which o1 is superior is that of safety. OpenA1 states: As part of developing these new models, we have come up with a new safety training approach that harnesses their reasoning capabilities to make them adhere to safety and alignment guidelines. By being able to reason about our safety rules in context, it can apply them more effectively. A comparison of GPT-4o with o1 using a of our OpenAI;s hardest jailbreaking tests, which measures how well the model continues to follow its safety rules if a user tries to bypass them, GPT-4o scored 22 (on a scale of 0-100) while o1-preview scored 84. While OpenAI's announcements don't explicitly mention the "Strawberry" codename, you'll find a reference to it in one of the examples that showcase the new chain of thought process used by o1-preview. Scroll through the Cipher problem to the end to see:
If you are mystified by this, you need to know that one of ChatGPT's famous hallucinations was that there are two Rs in "Strawberry" - patently incorrect, even to dyslexics. The good news for developers is that o1-preview outperforms GPT4-o by a huge margin, justifying OpenAI's claim that: The o1 series excels at accurately generating and debugging complex code. Moreover, OpenAI has also released a smaller model, o1-mini, targeted at applications that require reasoning but not broad world knowledge. It is 80% cheaper than o1-preview, making it more affordable, OpenAI is also planning to extend access to o1-mini to all ChatGPT Free users.
More InformationRelated ArticlesOpenAI Introduces GPT-4o, Loses Sutskever Google Rebrands Bard As Gemini With Subscription Gemini Offers Huge Context Window JetBrains AI Coding Assistant Now Generally Available Anthropic Launches Prompt Caching With Claude Tell A Chatbot "Take a deep breath ..." For Better Answers Pain And Panic Over Rogue AI - We Need a Balance Chat GPT 4 - Still Not Telling The Whole Truth Open AI And Microsoft Exciting Times For AI The Unreasonable Effectiveness Of GPT-3 To be informed about new articles on I Programmer, sign up for our weekly newsletter, subscribe to the RSS feed and follow us on Twitter, Facebook or Linkedin. 
Comments
or email your comment to: comments@i-programmer.info |
|||
| Last Updated ( Wednesday, 26 February 2025 ) |