| DeepMind Solves Math Olympiad And Proves Not Everything Is An LLM |
| Written by Mike James | |||
| Wednesday, 31 July 2024 | |||
|
The amazing recent advances in AI have been mostly driven by Large Language, or Foundational, Models, but neural networks come in more than one form and Deep Mind is still pushing on in other directions. It seems fairly clear to most that LLMs are great at what they do, but to achieve a more useful sort of AI we are going to need to augment them with other learning systems. After all, the human brain isn't a single undifferentiated lump of connected neurons - it has subsystems that do specific things.
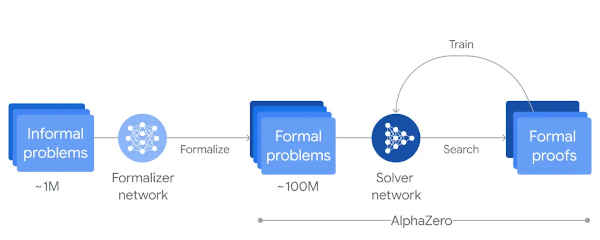
DeepMind has taken Google's Gemini LLM and used it as a front end to a modified AlphaZero, which is a deep reinforcement learning model. AlphaZero has previously proved to be good at games such as Go and Chess and has been modified into practically useful areas, such as AlphaFold working out how proteins fold. Mathematical problems are initially difficult for reinforcement learning systems because they are expressed in vague and difficult-to-understand natural language. The role of Gemini is to convert the imprecise formulation into a formal language - Lean - which is a language specifically designed to be used by proof assistants. The standard Gemini language model was fine-tuned on examples of English to Lean. Given this more precise input, AlphaZero was then trained on many different mathematical problems to either prove or disprove them.
Alongside this effort, AlphaGeometry 2 was developed as an improvment on the first version by being trained on lots of generated data concerning the relationships between objects, angles and so on. It too uses Gemini as a front end to convert the natural language problem into a symbolic representation. To test these systems out, DeepMind set them the task of solving six problems from this year's International Mathematical Olympiad using both AI systems. This is a yearly contest aimed at high school students and the standard is usually very high. Normally students get nine hours to solve the problems but AlphaProof took only a few minutes for one problem and three days for another. This is clearly a mixed result, but good enough for it to qualify for a silver medal with 28 points, missing a gold medal by one point. Only 58 of the 609 human contestants achievd the same level. For example: AlphaProof managed to solve: Determine all real numbers α such that, for every positive integer n, the integer (Note that ⌊z⌋ denotes the greatest integer less than or equal to z. For example, ⌊−π⌋ = −4 and ⌊2⌋ = ⌊2.9⌋ = 2.) Solution: α is an even integer. Clearly LLM have a bright future as front ends to other types of neural networks. This is just the start of practical AI.
More InformationAI achieves silver-medal standard solving International Mathematical Olympiad problems Related ArticlesCan DeepMind's Alpha Code Outperform Human Coders? Can Google DeepMind Win At AI? DeepMind Solves Quantum Chemistry Why AlphaGo Changes Everything AlphaFold Solves Fundamental Biology Problem AlphaFold DeepMind's Protein Structure Breakthrough Deep Learning Researchers To Work For Google Google's Large Language Model Takes Control To be informed about new articles on I Programmer, sign up for our weekly newsletter, subscribe to the RSS feed and follow us on Twitter, Facebook or Linkedin. 
Comments
or email your comment to: comments@i-programmer.info |
|||
| Last Updated ( Wednesday, 31 July 2024 ) |