| SparklyR - An R Interface For Spark |
| Written by Kay Ewbank |
| Friday, 21 October 2016 |
|
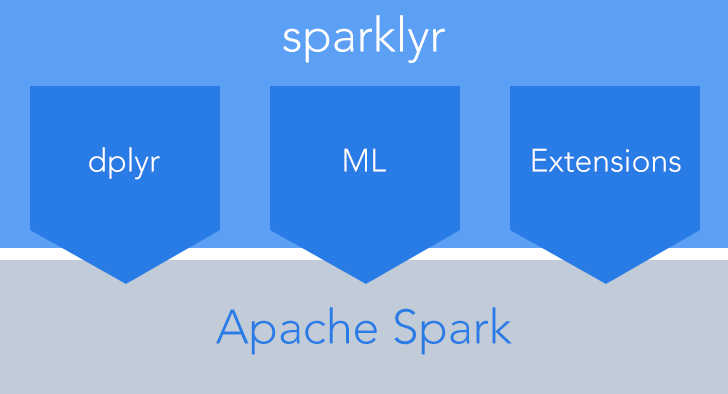
The team behind R Studio has announced sparklyr, a new package that provides an interface between R and Apache Spark. The new package aims to fulfil the need for a native dplyr interface to Spark, and to provide interfaces to Spark’s distributed machine learning algorithms. Dplyr is a package that provides a set of tools that you can use to manipulate datasets in R. It's a development from plyr, focusing on only data frames.
The new package lets you interactively manipulate Spark data using both dplyr and SQL (via DBI). You can filter and aggregate Spark datasets, then bring them into R for analysis and visualization. The package can also be used to orchestrate distributed machine learning from R using either Spark MLlib or H2O SparkingWater. Both provide a set of high-level APIs built on top of DataFrames that help you create and tune machine learning workflows. Developers can also extend the package via the extensions that call the full Spark API and provide interfaces to Spark packages, as the facilities used internally by sparklyr for its dplyr and machine learning interfaces are available to extension packages. You can set up Spark connections and browse Spark data frames within the RStudio IDE using SparklyR, and it also lets you connect to Spark from R via the integrated dplyr backend.
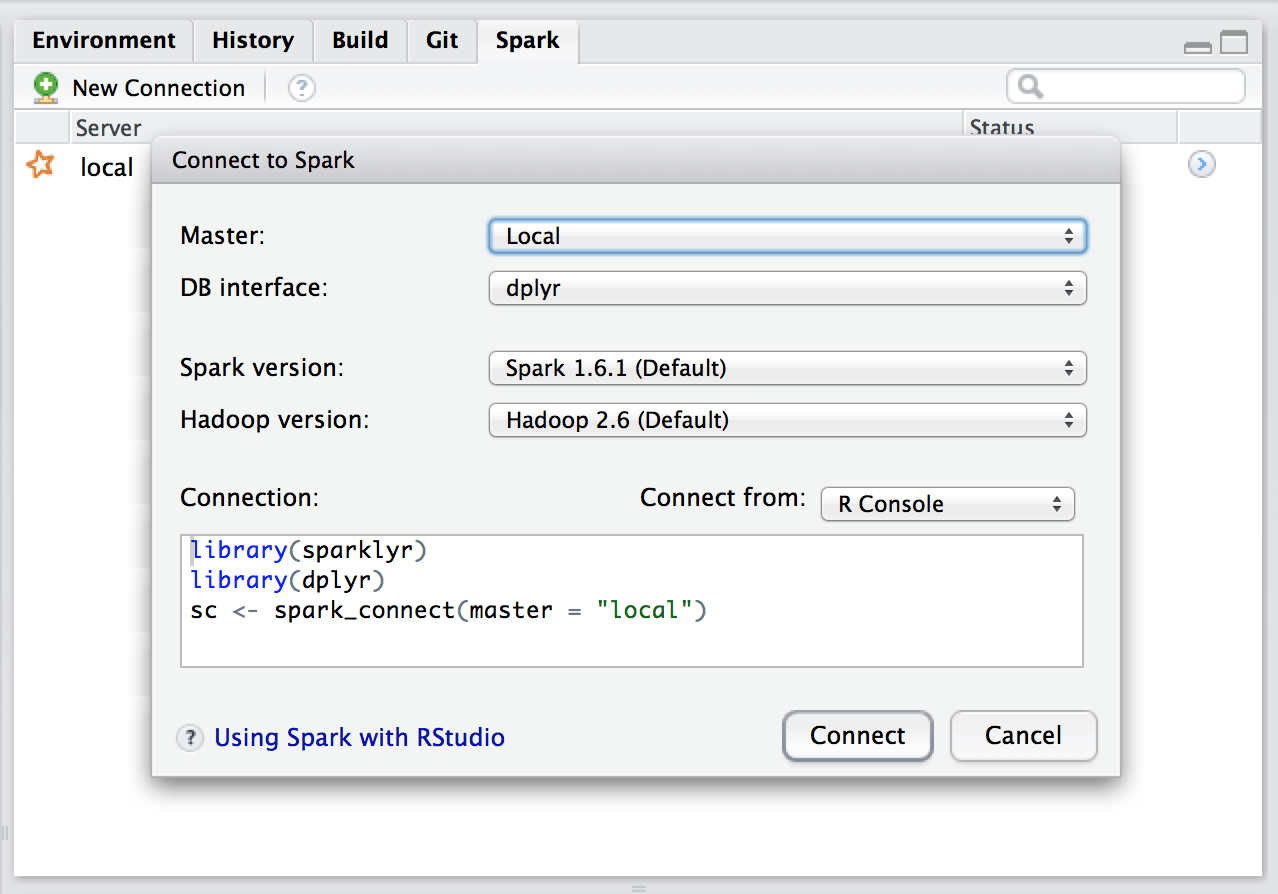
The latest RStudio Preview Release of the RStudio IDE includes integrated support for Spark and the sparklyr package, including tools for:
The final version of RStudio IDE that includes integrated support for sparklyr will ship within the next few weeks.
More InformationRelated ArticlesApache Spark Technical Preview A Programmer's Guide to R - Data and Objects
To be informed about new articles on I Programmer, sign up for our weekly newsletter,subscribe to the RSS feed and follow us on, Twitter, Facebook, Google+ or Linkedin.

Comments
or email your comment to: comments@i-programmer.info |
| Last Updated ( Sunday, 06 November 2016 ) |