| Speech2Face - Give Me The Voice And I Will Give You The Face |
| Written by Mike James | |||
| Sunday, 16 June 2019 | |||
|
Neural networks are good at spotting patterns and correlations in data, but are they good enough to recreate the face that produced a particular voice? Neural networks often do useful jobs, like recognizing text or spoken words, in addition they can often tell you how much information there is in the data. If you can train a neural network to predict Y based on X then there is presumably enough information in X to to determine Y to some extent. The problem is that being able to predict is often taken as an indication of causality in some form or another.
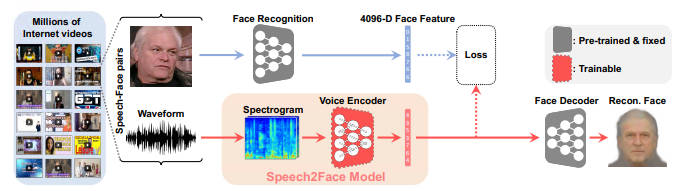
In this case we have a neural network that predicts what someone looks like based on a voice sample. Take lots of images of people talking and feed them through a face recognition neural network and derive a 4096 dimensional face vector. Next take the voice sample and use it to train another neural network to create the face vector. Slowly the network learns to reproduce the face from the voice on the training data and, as is the way with neural networks, it then goes on to predict faces from voice on data it hasn't seem. So how does it do? The first column of pictures is the real face, the second is the face reconstructed from the face vector used to train the network and the third is the face reconstructed from the voice sample: I don't know about you, but I think its amazingly good. However, we need to be clear about what has been learned. There are clearly some physical features of the face that are going to modify the voice - change frequencies, speed, etc. Presumably pitch is an important feature in determining gender and hence things like hair and beards. However, it seems likely that social factors will also be coded into speech and this will allow the network to predict features that you might not think would modify the physical nature of the voice. The researchers conclude: We have presented a novel study of face reconstruction directly from the audio recording of a person speaking. We address this problem by learning to align the feature space of speech with that of a pre-trained face decoder using millions of natural videos of people speaking. We have demonstrated that our method can predict plausible faces with the facial attributes consistent with those of real images They are also worried about the ethics and issues inherent in the work: As mentioned, our method cannot recover the true identity of a person from their voice (i.e., an exact image of their face). This is because our model is trained to capture visual features (related to age, gender, etc.) that are common to many individuals, and only in cases where there is strong enough evidence to connect those visual features with vocal/speech attributes in the data (see “voice-face correlations” below). As such, the model will only produce average-looking faces, with characteristic visual features that are correlated with the input speech. It will not produce images of specific individuals. This is true enough, but I can well imagine some law enforcement agency using it to generate a likeness of say a terrorist based on a phoned-in threat. Is this OK or is there too much chance of neural network hallucination working its way into the output. The big problem, and it has been for a while, is that neural networks come with few, or usually no, estimates of how accurate they are. This is as subjective as a human artist listening to a voice and then drawing a face, but it gives every impression of being more objective than this. Here are some fails from the paper:
I'm impressed and I think it could be useful, but it could so easily go very wrong.
More InformationSpeech2Face: Learning the Face Behind a Voice Tae-Hyun Oh, Tali Dekel, Changil Kim, Inbar Mosseri, William T. Freeman, Michael Rubinstein and Wojciech Matusik Related ArticlesGANs Create Talking Avatars From One Photo AI News Anchor - A First For China Deep Angel-The AI of Future Media Manipulation More Efficient Style Transfer Algorithm 3D Face Reconstruction Applied to Art Find Your 2000-Year-Old Double With Face Recognition A Neural Net Creates Movies In The Style Of Any Artist Style Transfer Applied To Cooking - The Case Of The French Sukiyaki To be informed about new articles on I Programmer, sign up for our weekly newsletter, subscribe to the RSS feed and follow us on Twitter, Facebook or Linkedin. 
Comments
or email your comment to: comments@i-programmer.info
|
|||
| Last Updated ( Sunday, 16 June 2019 ) |