| Inside Bitcoin - The Block Chain |
| Written by Mike James | |||||||
| Thursday, 30 December 2021 | |||||||
Page 3 of 3
ValidationWhen a node completes the proof of work task the block that they have been working on is ready to be included in the block chain. At this point the node can submit the block to all the other nodes for inclusion in the official chain - the nodes also check the block for consistency at this point and once again make sure that a transaction doesn't spend a Bitcoin twice. Once the block is validated and submitted to the system the transactions within it have received one confirmation. Notice that this doesn't mean that the transactions are good. The reason is that there are lots of copies fo the database being updated asynchronously across the network and it is just possible that two or more nodes solved the problem at more or less the same time and some copies of the database might have been updated with a different "next block". At this point the split in the database cannot be detected by a distibuted system and therefore there can be no attempt to correct it - each node thinks it has the correct chain
However at the next step the block generated either fits uniquely into copy A or copy B of the database. Remember each new block includes a reference to the previous last block so you can move blocks between slightly different versions of the block chain. Suppose two nodes attempt to continue the two chains:
If the block that wins the proof of work and is sent out to the rest of the database continues copy B and not copy A then copy A is discarded and copy B becomes the one true database.
Of course it could be that by chance two nodes complete their task at the roughly the same time and the database splits again" However as time goes on this becomes increasingly unlikely and eventually one database will win out as the true record of how the Bitcoins have been transferred. Thus after six more valid blocks have been added to the chain that the transaction belongs to its status is changed to confirmed. The idea is that after six more transaction blocks have been processed the original block is well and truly embedded in Bitcoin history never to be undone. Again the fact that the blocks have been constructed to fit together one after another means you can't easily update a single block without throwing away all of the blocks that follow. What this means is that a user spends a Bitcoin and then has to wait until the transaction is confirmed for the transaction to become permanent. If the user is dishonest and tries to spend the Bitcoin twice then the probability is very high that only one transaction will reach the status of having six following validated blocks and so one transaction will fail and the other succeed. Given that it takes about 10 minutes for each block to be added it takes about an hour to get to six confirmations - which is one reason why Bitcoin isn't a great way to pay for goods. In some cases a trader will take a Bitcoin payment with zero confirmation so as to make the transaction immediate but as you can appreciate this is essentially just putting your trust in the honesty of the customer. CheatingSo it is very likely that even though the database is distributed and updated asynchronously a single coherent history of transactions is eventually agreed upon. Notice that this is still a probabilistic statement and it could conceivably go wrong but the probability is very low - unless someone finds a way to make it happen. The need to do work makes the system dependent on the fact that the majority of CPUs engaged in the network are honest. However, if you had enough computing power at your disposal then you might be able to fool the system by solving two different blocks before anyone else could. In this situation you would be able to get two versions of a transaction's history, so allowing you to spend the same Bitcoins twice say. However, to keep this up you would have to repeat the sting, not once but six more times and maintain the split in the database. This seems like a very difficult task. There may be something in the implementation of the idea that makes it vulnerable to manipulation but the basic idea seems good. The futureTo a programmer the proof of work method of ensuring the acceptance of a single valid distributed database that is updated asynchronously is fascinating and it certainly has other applications. There are a number companies planning to make use of the block chain technology to maintain distributed decentralized ledgers and many are of the opinion that this is the real importance of Bitcoin. As far as mining goes there are bit problems ahead. As the value of Bitcoin rose so it became possible to invest large sums of money into building mining rigs and million dollar mining data centers now do most of the work. This has caused the difficulty of the proof of work to increase. No longer can you make a profit mining Bitcoin with a desktop machine even if it has a powerful GPU. This causes a number of worries. It is now possible for a small number of mining operations to control more than 50% of the mining capacity and this is more than the fraction that it is assumed needed to control the Bitcoin ledger. So far no miner has been discovered to be making use of this power. Another problem is that the large mining data centers cost a lot to run and as the reward for mining falls a lot depends on the value of Bitcoin. If the value falls then it might not be economically viable for the miners to burn so much electricity and they will stop. A more general problem is the current block size. As a block is only added to the block chain every ten minutes the maximum transaction rate is about 3 transactions per second - whcih should be compared to the 20,000 plus transactions per second on the VISA network. Currently there is an argument going on in the Bitcoin community as to whether or not the block size should be increased. More interesting from a programmer's point of view is what happens when the database gets too big for a single machine to work with. At the moment it is about 40GBytes and every node works with the entire database. The interesting news is that the database already has a Merkle hash tree to enable it to be used piecemeal secure in the knowledge that it hasn't been tampered with - but Merkle trees are another story. More information
The recent history of Bitcoin has been particularly turbulent and you can find out much more by reading some of the following:
Bitcoin Isn't As Anonymous As You Might Hope Replace By Fee - Bitcoin Modifications Bitcoin Fork Due To Algorithmic Differences Linux Foundation Backs Blockchain Project Bitcoin Difficulty Jumps - A 50% Miner Is Possible Bitcoin - A Failed Experiment. Related ArticlesStanford Bitcoin Engineering MOOC Proposed
To be informed about new articles on I Programmer, sign up for our weekly newsletter, subscribe to the RSS feed and follow us on Twitter, Facebook or Linkedin.
Comments
or email your comment to: comments@i-programmer.info 
<ASIN:1491920491> <ASIN:1785287303> <ASIN:0996061312> <ASIN:1119076137> |
|||||||
| Last Updated ( Thursday, 30 December 2021 ) |
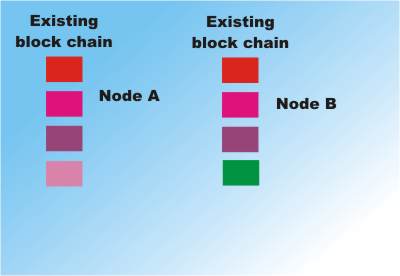 Two nodes have different chains due to being updated by two different successful solutions to blocks in different parts of the network
Two nodes have different chains due to being updated by two different successful solutions to blocks in different parts of the network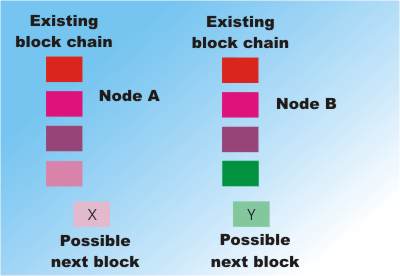 Two candidate blocks but X only fits the end of chain A and Y only fits the end of chain B.
Two candidate blocks but X only fits the end of chain A and Y only fits the end of chain B.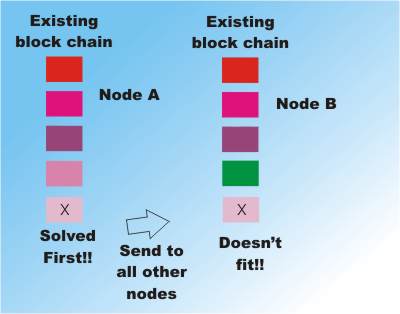 Chain B now becomes the "bad chain" because it cannot be updated by the winning block. Note that Chain A would have been the "bad chain" if chain B's block had finished first!
Chain B now becomes the "bad chain" because it cannot be updated by the winning block. Note that Chain A would have been the "bad chain" if chain B's block had finished first!