| The Bloom Filter |
| Written by Mike James | ||||||||
| Thursday, 23 June 2022 | ||||||||
Page 2 of 2
A Bloom filter in C#To make sure that you follow the way the Bloom filter actually works let's implement a simple version in C#. This is not a production version and it certainly isn't optimized. Optimization would depend very much on what you were using it for. What this implementation does is focus your attention on some of the difficulties of implementing a good Bloom filter. The first simplicity is that instead of custom crafting a bit array we can use the supplied BitArray object. This can be found in the Collections namespace:
We can also create a Bloom filter class:
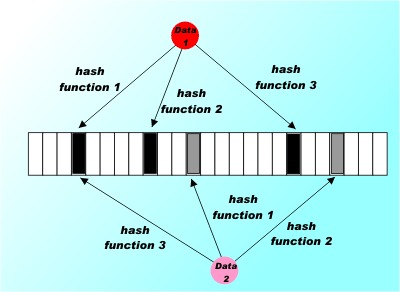
The constants m and k set the size of the bit array and the number of hash functions to use. Before we can do anything else we need to solve the problem of finding k hash functions. This is difficult because finding one hash function is tough to find k is very tough. Fortunately there are a number of easy ways out of the problem. The first is that we can use the built in GetHashCode method that is built into every string. While this is not likely to be optimized it is supposed to be good enough for hash storage. This gives us one hash function. The simplest way to generate k-1 more is to use the hash value as the seed for a random number generator and use the next k-1 random numbers as additional hash values. This isn't ideal and in practice it tends to produce a Bloom filter that is about as good in terms of false positives as using k/2 true hash values. An alternative way of doing that job that is nearly as efficient is to generate two independent hash values h0 and h1 and then forming:
for i = 2,,, k-1. This is easy but it needs two independent hash functions and this would mean having to actually code one in C#. The simple random number solution to finding k hash values is very easy to implement:
When the method returns we have k hash values in an int array ready to be used. The Bloom class needs two other methods. One to add a data value:
Notice the way that the BitArray uses a Set method to set the bit at the correct location to either true i.e. 1 or false i.e. 0. When this method returns all of the locations indicated by the hash array have been set to 1. The final method is the one that looks up a value to see it if is already in the filter:
This has to simply scan the locations indicated by the hash array and return true if they are all true. Notice that the only certainty is if you find a false i.e.0 BitArray element because then you can be sure that the string has never been entered into the filter. To try it out you would do something like:
and to lookup a string:
Of course in a real situation you would add lots of data and look up lots of data. If you plan to make use of a Bloom filter then it is worth first writing two good independent hash functions. However you are also going to want to implement it using something closer to the machine-like C, if not assembler, to get the final drop of performance out of it.
Related articlesHashing solves one of the basic problems of computing - finding something that you have stored somewhere. Extensible hashing and perfect hashing are ideas that are worth exploring. A Bloom filter that you can delete, retrieve and list all data values. A look at a way of creating a set of hash functions More InformationPaper on using two hash values to create more: Less Hashing, Same Performance… MurmurHash - a good general purpose hash.
Killer Algorithms
Contents
* First Draft
Comments
or email your comment to: comments@i-programmer.info To be informed about new articles on I Programmer, sign up for our weekly newsletter, subscribe to the RSS feed and follow us on Twitter, Facebook or Linkedin. 
|
||||||||
| Last Updated ( Saturday, 25 June 2022 ) |