| Programmer's Guide To Theory - Kolmogorov Complexity |
| Written by Mike James | ||||||
| Monday, 22 June 2020 | ||||||
Page 2 of 2
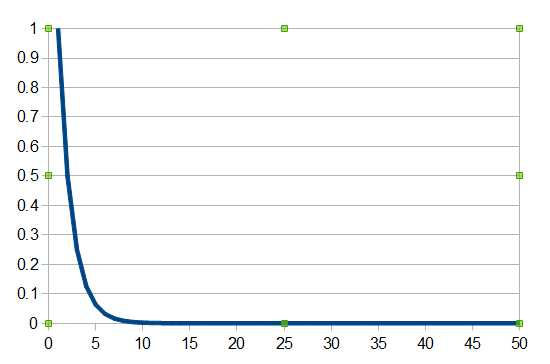
Kolmogorov Complexity Is Not ComputableThe second difficulty inherent in the measure of Kolmogorov complexity is that, given a random-looking string, you can't really be sure that there isn't a simple program that generates it. This situation is slightly worse than it seems because you can prove that the Kolmogorov complexity of a string is itself a non-computable function. That is, there is no program (or function) that can take a string and output its Kolmogorov complexity. The proof of this, in the long tradition of such non-computable proofs, is proof by contradiction. If you assume that you have a program that will work out the Kolmogorov complexity of any old string, then you can use this to generate the string using a smaller program and hence you get a contradiction. To see that this is so, suppose we have a function Kcomplex(S) which will return the Kolmogorov complexity of any string S. Now suppose we use this in an algorithm: for I = 1 to infinity for all strings S of length I if Kcomplex(S)> K then return S You can see the intent, for each length of string test each string until its complexity is greater than K, and there seems like there is nothing wrong with this. Now suppose that the size of this function is N, then any string it generates has a Kolmogorov complexity of N or less. If you set K to N or any value larger than N you immediately see the problem. Suppose the algorithm returns S with a complexity greater than K, but S has just been produced by an algorithm that is N in size and hence string S has a complexity of N or less - a contradiction. This is similar to the reasonably well known Berry paradox: “The smallest positive integer that cannot be defined in fewer than twenty English words” Consider the statement to be a program that specifies the number n which is indeed the smallest positive integer that cannot be defined in fewer than twenty English words. Then it cannot be the number as it has just been defined in 14 words. Notice that once again we have a paradox courtesy of self-reference. However, this isn't to say that all is lost. CompressabilityYou can estimate the Kolmogorov complexity for any string fairly easily. If a string is of length L and you run it through a compression algorithm you get a representation which is L-C in length where C is the number of characters removed in the compression. You can see that this compression factor is related to the length of a program that generates the string, i.e. you can generate the string from a description that is only L-C characters plus the decompression program. Any string which cannot be compressed by even one character is called incompressible. There have to be incompressible strings because, by another counting argument, there are 2n strings of length n but only 2n-1 strings of length less than n. That is, there aren't enough shorter strings to represent all of the strings of length n. Again we can go further and prove that most strings aren't significantly compressible, i.e. the majority of strings have a high Kolmogorov complexity. The theory says that if you pick a string of length n at random then the probably that it is compressible by c is given by 1-21-c+2-n. Plotting the probability of compressing a string by c characters for a string length of 50 you can see at once that most strings are fairly incompressible once you reach a c of about 5.
In chapter but not in this extract
Summary
A Programmers Guide To Theory
Now available as a paperback and ebook from Amazon.
Contents
To be informed about new articles on I Programmer, sign up for our weekly newsletter, subscribe to the RSS feed and follow us on Twitter, Facebook or Linkedin. 
Comments
or email your comment to: comments@i-programmer.info |
||||||
| Last Updated ( Monday, 22 June 2020 ) |