| .NET For Apache Spark Updated |
| Written by Kay Ewbank | |||
| Thursday, 05 November 2020 | |||
|
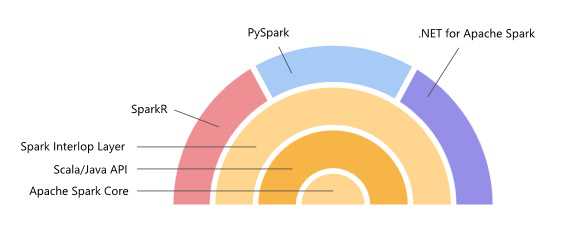
The .NET bindings for Spark have been updated. The new 1.0 version adds support for .NET apps targeting .NET Standard 2.0 or later, as well as support for Apache Spark DataFrame APIs. Spark is the general-purpose cluster computing framework that has native support for distributed SQL and enables streaming, graph processing, and machine learning. The .NET bindings for Spark are written on the Spark interop layer, and provide high performance bindings to multiple languages. Until their introduction Spark was accessible by coding using Scala, Java, Python or R but not .NET.
The improvements to the 1.0 release of .NET for Apache Spark start with the support for .NET applications targeting .NET Standard 2.0. In practical terms, it also now lets you use the Spark DataFrame APIs, including the ability to write Spark SQL. You can also write Spark apps using .NET user-defined functions.
The library now comes with an API extension framework to add support for additional Spark libraries. Currently this includes Linux foundation Delta Lake, Microsoft OSS Hyperspace, ML.NET, and support for Apache Spark’s MLLib functionality. The developers have improved the performance when using Apache Arrow to move data between the Spark runtime and .NET UDFs, and have also improved the features available for this. Overall, the team says that apps using .NET for Apache Spark that are not using UDFs show the same speed as Scala and PySpark-based non-UDF Spark applications. If the applications include UDFs, the .apps are at least as fast as PySpark programs, often faster. Future plans include supporting deployment options, including integration with CI/CD DevOps pipelines and publishing or submitting jobs directly from Visual Studio.
More Information.NET For Apache Spark On GitHub .NET For Apache Spark On Microsoft Related ArticlesHave Your Say On .NET For Spark Visual Spark Studio IDE For Spark Apps Spark BI Gets Fine Grain Security Microsoft Asks For Help On The Future Of .NET - Where Do We Start?
To be informed about new articles on I Programmer, sign up for our weekly newsletter, subscribe to the RSS feed and follow us on Twitter, Facebook or Linkedin. 
Comments
or email your comment to: comments@i-programmer.info |