| MapR Releases Docker Container For Local Development |
| Written by Kay Ewbank | |||
| Friday, 26 January 2018 | |||
|
MapR has released a Docker container made up of Drill, Apache Spark, the MapR file system, and MapR-DB that provides a really useful option for any developer who wants a simple way to try out big data development. MapR provides direct processing of a wide range of big data sources from a single computer cluster, and now lets you load data into files, tables, and streams and work with it in analytical engines such as Spark and Drill from mainstream IDEs, without having to set up your own servers and configure your own analytical engine. The container has been designed to let developers run a single node MapR cluster on their laptop, then work with data using the products of the MapR platform directly from IDEs, database clients, and other software development tools. The video below shows how the container can be used:
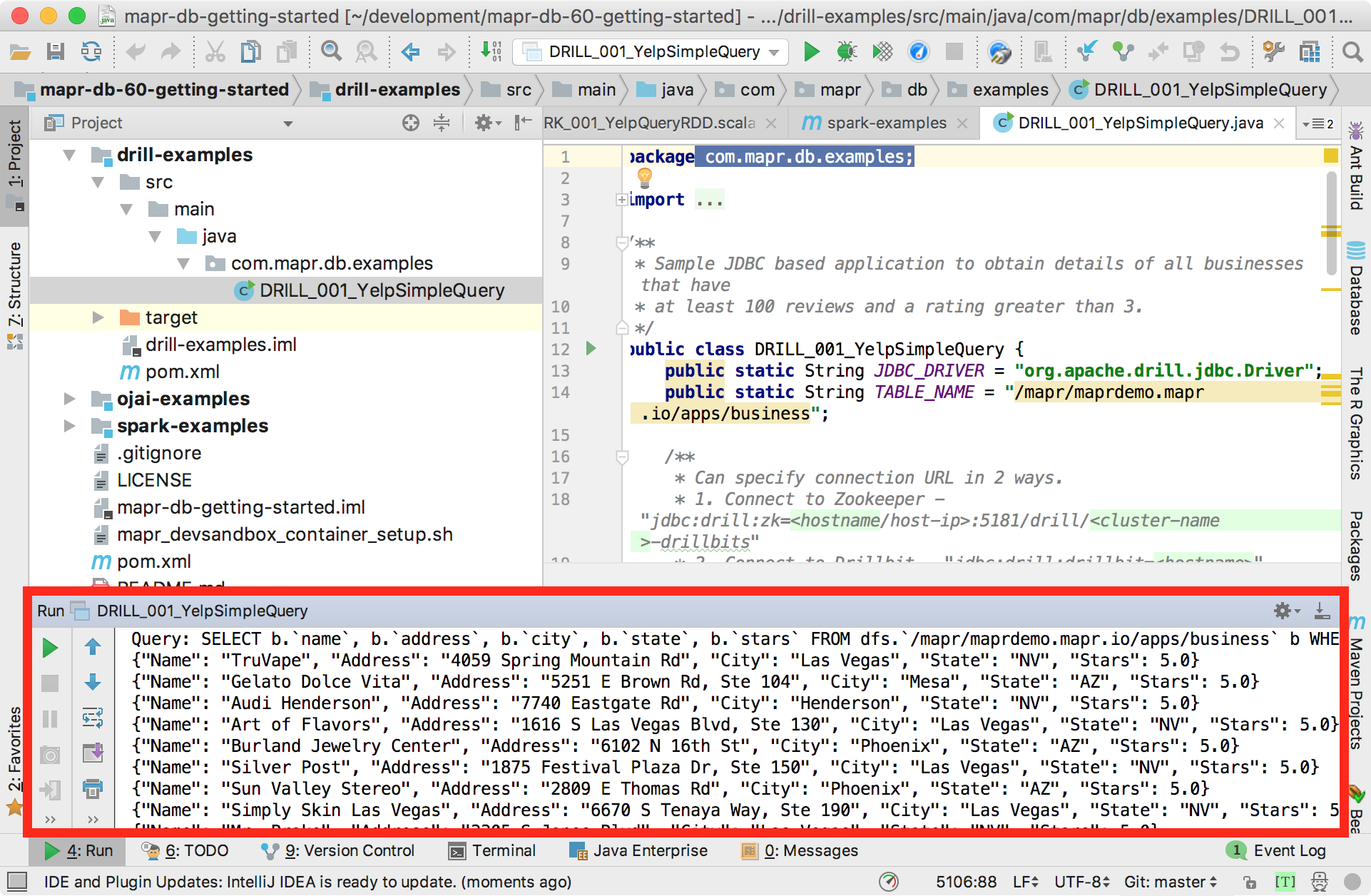
The container is free to use, and comes with a number of components, starting with the Drill and Spark analytical engines. Apache Drill is a distributed SQL query engine that works with most non-relational datastores, including HBase, MongoDB, MapR-DB, HDFS, MapR-FS, Amazon S3, Azure Blob Storage, Google Cloud Storage, Swift, NAS and local files. A single query can join data from multiple datastores. This pic (from the MapR blog) shows the container being used to work with data in Drill from IntelliJ:
Apache Spark is Apache's data processing engine for processing and analyzing large amounts of data. It is implemented in Scala and Java, and runs on a cluster. Spark and Drill are accessible in the MapR Docker container either via their respective APIs programmatically or with command line tools such as The next element in the container is a copy of the MapR Control System, the primary web interface for controlling a MapR cluster. The The MapR-XD file system is also included to provide a way of managing distributed storage. XD can be used for managing files, objects and containers. You also get the MapR-DB NoSQL database that can be used to manage and store JSON and binary data. MapR-DB can be worked with using either the Open JSON Application Interface (OJAI) API, HBase API, or with the command line tools The final element in the container is MapR Streams. This can be used for distributed storage for real-time data, and you can work with it for publishing and consuming messages to streams using the Kafka API or Spark Streaming API. More InformationMapR Docker Container Overview Related ArticlesMapR-DB Adds Native Secondary Indexes Apache Spark With Structured Streaming To be informed about new articles on I Programmer, sign up for our weekly newsletter, subscribe to the RSS feed and follow us on Twitter, Facebook or Linkedin.

Comments
or email your comment to: comments@i-programmer.info |
|||
| Last Updated ( Friday, 26 January 2018 ) |