| Getting Going With RAG |
| Written by Nikos Vaggalis | |||
| Monday, 20 January 2025 | |||
|
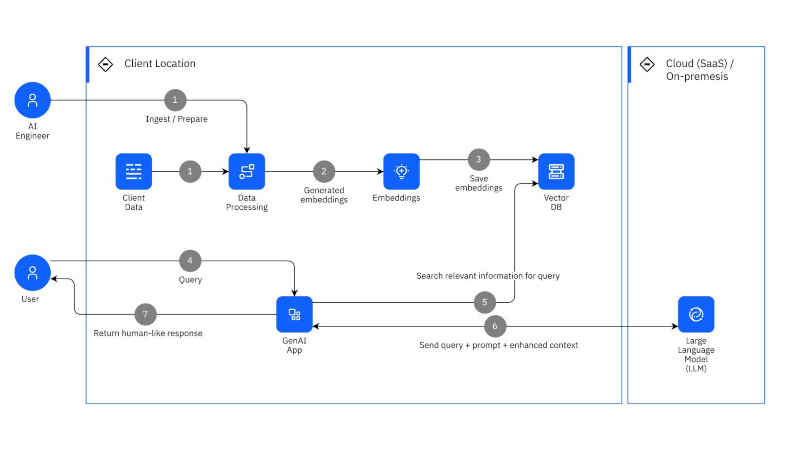
IBM has produced a cookbook of tips and methodologies on how to use RAG to power up any kind of business applications. Microsoft and Docling both provide tools for data ingestion from a range of document formats I talked about the value of RAG in my recent article RAG from Scratch explaining why this technique is preferable to fine-tuning: RAG allows LLMs to amplify the user's query by connecting to external data in real time when generating their output. There are plenty of tutorials on the topic of RAG, but few are as high quality as Langchain's RAG from Scratch, as examined in the homonymous article. Well here's another one, this time from IBM. The IBM RAG Cookbook is not a simple tutorial though; it provides an insider's view and end-to-end coverage of the entire RAG pipeline, from document ingestion and answer generation to system evaluation. It might have been considered as an indirect advertisement for IBM's AI platform watson.x if it didn't incorporate solutions done with open-source frameworks like LangChain and LlamaIndex. As such the cookbook caters for all audiences; developers looking for open source solutions or enterprises evaluating and building products on the watson.x platform. Its material is split into the following categories:
Seen as steps, when combined and applied in turn, result in the RAG pipeline which subsequent output being the anticipated business application.
Each category is showcased using both the watson.x platform and its open source counterparts. For instance, in the Data Ingestion category: Ingestion is the process of parsing information from source documents so that it can be embedded into a search space for later retrieval. While this is a straightforward process for plain text complications arise when the source documents are in non 'text' formats, eg. Microsoft Word or PDF, and when they contain complex formatting such as repeating headers and footers, text in multiple columns, or tables. Three alternatives are offered:
These are followed by practical examples of ingesting documents in all three cases. The underlying data-ingestion open-source libraries used in converting PDFs to plain text are PyPDFLoader and PyMuPDF, which of course do their job well, but usually PDF is not the only document format found in an enterprise's data silo; As far as its Office documents go, Microsoft has recently released the MarkItDown utility which converts various file formats to markdown:
Docling is an alternative solution for parsing documents and exporting them to the desired format in preparation for gen AI that is gaining ground fast. From IBM Deep Search it is open-sourced under an MIT License and can read PDF, DOCX, PPTX, XLSX, Images, HTML, AsciiDoc & Markdown and export them to to HTML, Markdown and JSON with embedded and referenced images.
The rest of the sections of the IBM Cookbook follow the same pattern, but I'd like to highlight the one onChunking. Effective chunking methodologies are crucial for optimizing search performance and relevance, as such there isn't consensus on what the best way is. This section is offering the most comprehensive overview I've ever encountered by comparing the various chunking techniques available and when each one is the most appropriate in using. The rest of the narrative follows the pipeline through Embedding to finally an overview of providing an UI for your application. To sum it up, this is really good and insightful content recommended whether you are an IBM customer or just a developer looking to utilize RAG.
More InformationIntroducing the IBM RAG Cookbook Related Articles
To be informed about new articles on I Programmer, sign up for our weekly newsletter, subscribe to the RSS feed and follow us on Twitter, Facebook or Linkedin. 
Comments
or email your comment to: comments@i-programmer.info |
|||
| Last Updated ( Monday, 20 January 2025 ) |