| GPT-4 Doesn't Quite Pass The Turing Test |
| Written by Mike James | |||
| Wednesday, 01 November 2023 | |||
|
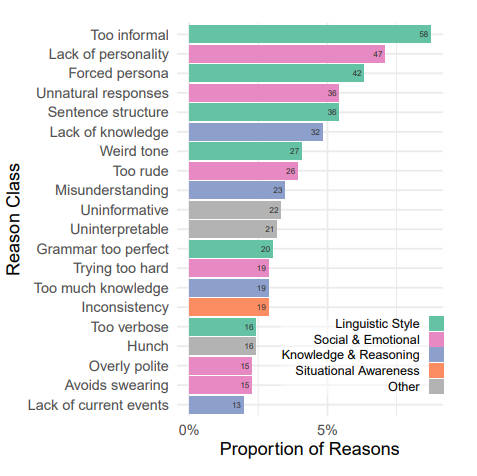
People have assumed that Large Language Models have passed the Turing test, but have they? And if not how do they fail? Large Language Models (LLMs) like GPT-4 are so eloquent that surely they pass the Turing Test? Two researchers from UC San Diego put the question to the test with an online Turing Test and the results are very interesting. The test was conducted with a single human interrogator trying to decide if the subject is an AI or a human. The AI was GPT-3.5 or GPT-4 with a range of configurations. The key part of the experiment is the use of a prompt to put the LLM into the "right frame of mind". It suggested a personality for the agent and how to respond. The prompt was varied to see if there was any difference, but there exists the possibility that the outcome depends on the prompt to a greater degree than imagined. Each session lasted 5 minutes and each message was to be less than 300 characters. 652 judges completed 1810 games, which were reduced to 1405 after removing games that were suspect in some way or other. Humans managed to convince their interrogator that they were human 63% of the time, which is lower than you might expect, GPT-4 managed 41% and GPT-3.5 only managed 5% to 14%. To put this in perspective, the ages old ELIZA (1966) managed 27%! It was found the the prompt had a big effect on the outcome. GPT-4 varied from 41% to 6% in the worst case. Could there be a "golden" prompt that pushed the success rate over the 50% needed to be better than chance. Another interesting detail is why participants made their decisions. For example, the reasons that an AI was thought to be an AI are:
I'm not sure what I make of "Too informal" being at the top of the list means and what can you say about "Grammar too perfect"? Could these have been improved by tweaking the prompt? Also notice that lack of knowledge outranks too much knowledge, so perhaps some more learning is in order. The researchers conclude: "On the basis of the prompts used here, therefore, we do not find evidence that GPT-4 passes the Turing Test. Despite this, a success rate of 41% suggests that deception by AI models may already be likely, especially in contexts where human interlocutors are less alert to the possibility they are not speaking to a human. AI models that can robustly impersonate people could have could have widespread social and economic consequences." It seems reasonable that we should consider that there isn't just one Turing Test and the success of an LLMs depends on how prepared the interrogator is and on what prompt is used with the LLM. "It seems very likely that much more effective prompts exist, and therefore that our results underestimate GPT-4’s potential performance at the Turing Test." It still seems quite amazing to me that we have reached this point so fast. Only a short time ago the issues with public Turing Tests were to do with trickery and guile - now we seem to have something like real AI competing in an honest fashion. The conclusion of this research maybe that GPT-4 didn't quite make it, but for me the whole outcome indicates that it is at least a contender.
More InformationDoes GPT-4 Pass the Turing Test? Related ArticlesChat GPT 4 - Still Not Telling The Whole Truth Google's Large Language Model Takes Control The Year of AI Breakthroughs 2022 The Unreasonable Effectiveness Of GPT-3
To be informed about new articles on I Programmer, sign up for our weekly newsletter, subscribe to the RSS feed and follow us on Twitter, Facebook or Linkedin. 
Comments
or email your comment to: comments@i-programmer.info
|
|||
| Last Updated ( Wednesday, 01 November 2023 ) |