| RT-2 A Breakthrough For Robot Control |
| Written by Mike James | |||
| Wednesday, 16 August 2023 | |||
|
RT-2 is the new version of what Google calls its vision-language-action (VLA) model and at last we can start to see the potential in general purpose robots. While everyone is hyping AI chatbots, this is where the real revolution is happening. Google DeepMind has announced Robotic Transformer 2 (RT-2), a "first-of-its-kind" vision-language-action (VLA) model that uses data scraped from the Internet to enable better robotic control through plain language commands. The ultimate goal is to create general-purpose robots that can navigate human environments.
The key idea is that many things can be cast into a form of language and then they can be implemented using Large Language Models LLMs which are driving the success of AI at the moment. In this case robot actions are treated as a language. The language tokens are translated into actions and this how the robot performs a task. The second component is the Vision Language Module VLM which is trained on images presented to a convolutional network and a language model trained using language describing the images. VLMs can be used to caption images, describe images and so on - once trained you present them with an image and they generate text. In this case the text also includes robot instructions.
RT-1 was based on PaLM-E and one version of RT-2 still uses it and a second version uses PaLI-X - the two have slightly different strengths and weaknesses.
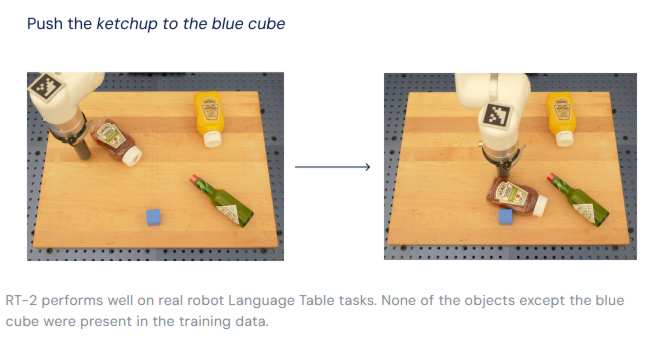
RT-2’s ability to transfer information to actions shows promise for robots to more rapidly adapt to novel situations and environments. In testing RT-2 models in more than 6,000 robotic trials, the team found that RT-2 functioned as well as the previous model, RT-1, on tasks in its training data, or “seen” tasks. And it almost doubled its performance on novel, unseen scenarios to 62% from RT-1’s 32%.
In other words, with RT-2, robots are able to learn more like we do — transferring learned concepts to new situations. This ability to generalize is very important. Unlike GPT3 and other language models, RT-2 cannot afford to hallucinate and return untruthful results - just think what it would mean. It is why it is very likely that the next big breakthrough in AI will come from "embodied" AI. That is, putting AI agents in control of a physical body ensures that reality rules and hallucinations are quickly beaten out of the system. Not only does RT-2 show how advances in AI are cascading rapidly into robotics, it shows enormous promise for more general-purpose robots. While there is still work to be done to enable helpful robots in human-centered environments, RT-2 shows us an exciting future for robotics just within grasp. You can't help but wonder what the result of using this sort of system with Spot or Atlas not to mention self driving cars. All of our current line up of top robots started out long before this sort of approach was possible.
More InformationWhat is RT-2: Speaking robot: Our new AI model translates vision and language into robotic actions RT-2: New model translates vision and language into action Paper: RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control Related ArticlesGoogle's Large Language Model Takes Control To be informed about new articles on I Programmer, sign up for our weekly newsletter, subscribe to the RSS feed and follow us on Twitter, Facebook or Linkedin. 
Comments
or email your comment to: comments@i-programmer.info |
|||
| Last Updated ( Wednesday, 16 August 2023 ) |