| Facebook Apollo NoSQL Database |
| Written by Kay Ewbank | |||
| Wednesday, 18 June 2014 | |||
|
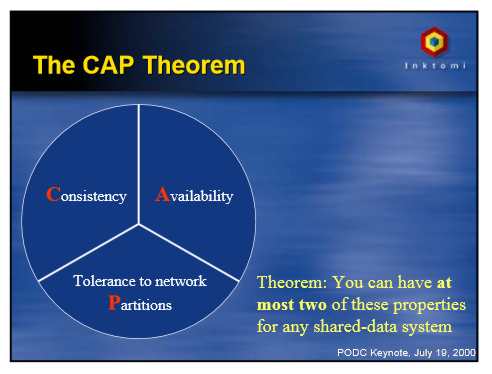
Facebook’s latest project is a NoSQL database called Apollo that provides online low latency hierarchical storage. The details of the database project were revealed at QCon New York on Wednesday by Jeff Johnson, a software engineer in Facebook’s Core Data group. He described Apollo as a distributed database around strong consistency using Paxos-style quorum protocols. Paxos is a family of quorum consensus protocols, originally defined for deriving a single agreed result from a number of possibilities on a network of unreliable processors. It can be used in replicated databases to overcome the problems caused if distributed servers fail. In order for an update to be accepted it must be voted on by a majority of servers within a shard, and updates are only completed when they make their way to a majority of servers. Distributed databases suffer from a problem described using the CAP or Brewer’s theorem, which states that a distributed database can’t achieve the following all at the same time:
The original paper on this was given by Dr. Eric Brewer of UC Berkeley at the Proceedings of the Annual ACM Symposium on Principles of Distributed Computing in 2000:
Distributed systems have to pick which two of C,A and P they choose, and Facebook has chosen CP, so that data is consistent between all nodes, and maintains partition tolerance so can work even should part of the network be unavailable. The tagline for Johnson’s presentation of Apollo is 'strong consistency at scale'. Facebook has four datacenters, with variable replication systems depending on the system – MySQL, HBase, or information services like caches or processing systems. Most replication systems in use at Facebook are asynchronous, master/slave type, with full copies of data, or at least notifications of the data, in other datacenters. The problem Facebook faces is that masters can fail, and the internet can fail, causing partitions, and the master/slave type replication suffers data unavailability and inconsistency issues.
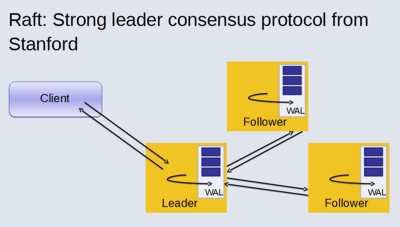
Apollo is an attempt to overcome this problem. The two main requirements are to provide atomic data transactions, and that acknowledged writes should eventually become visible and never be lost. Johnson says that “many NoSQL systems don’t offer this option, and it is problematic under last-writer-wins, where writers can’t serialize their actions. This is still subject to minority node failure and temporary partitions. It is a lot easier to provide these kinds of guarantees based on a CP-type system.” Johnson says that the sweet spot that Apollo is initially aiming for is online, low-latency storage, especially with flash and in-memory. The system isn’t just a K/V store, nor is it “document oriented”. Johnson says “We’re data structure oriented – strings, sets, maps, queues, trees, etc., like Redis, but hopefully stronger.” The design for Apollo is that of a hierarchy of thousands of shards, and Stanford Raft is used for consensus. Raft specifies that a leader from a quorum is chosen using a randomized leader election protocol. All nodes know who the leader is, and are able to distinguish between old and new leaders. RocksDB or MySQL can be used as underlying storage.
In addition to storing and querying data, Apollo can be used for the execution of user submitted code in the form of state machines. The main use of the fault tolerant state machines is system tasks such as shard creation or destruction, load balancing and data migration. However, users can also submit fault tolerant state machines. Apollo isn’t yet being used in production at Facebook, but may be used to replace some Memcached systems such as lookaside caches. Another early contender for Apollo is as a reliable, in-memory distributed database for Facebook, though this would require work on the kind of storage system used. Supporting the queues of various Facebook products such as outgoing Facebook message notifications for web and mobile users is another potential use. Message notifications are queued until they can be delivered to iOS, Android systems or SMS, and while the resident size of the data is small, the high throughput means many GBs of storage can be required in case the queues aren’t being drained properly due to message delivery problems. Apollo is still in development and could potentially be open sourced once the internal development settles down.
More InformationSlides from QCon (PowerPoint presentation) Related ArticlesMicrosoft Expands Redis Support RocksDB - Facebook's Database Now Open Source MariaDB 10.0 Beta Introduces Replication Enhancements Major Update to Google BigQuery BlinkDB Alpha of Approximate Query Engine Released Google's F1 - Scalable Alternative to MySQL
To be informed about new articles on I Programmer, install the I Programmer Toolbar, subscribe to the RSS feed, follow us on, Twitter, Facebook, Google+ or Linkedin, or sign up for our weekly newsletter.

Comments
or email your comment to: comments@i-programmer.info |
|||
| Last Updated ( Thursday, 19 June 2014 ) |
 Source: PODC Keynote 2000
Source: PODC Keynote 2000