| Google's F1 - Scalable Alternative to MySQL |
| Written by Kay Ewbank |
| Wednesday, 30 May 2012 |
|
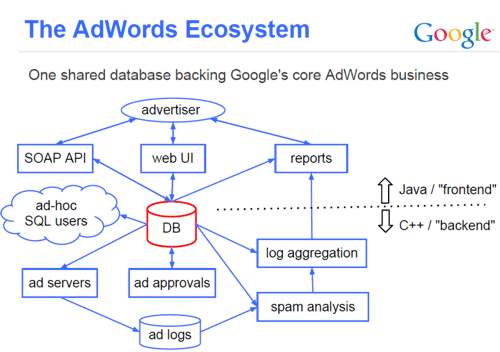
Google has moved its advertising services from MySQL to a new database, created in-house, called F1. The new system combines the best of NoSQL and SQL approaches. According to Google Research, many of the services that are critical to Google’s ad business have historically been backed by MySQL, but Google has recently migrated several of these services to F1, a new RDBMS developed at Google. The team at Google Research says that F1 gives the benefits of NoSQL systems (scalability, fault tolerance, transparent sharding, and cost benefits) with the ease of use and transactional support of an RDBMS. Google Research has developed F1 to provide relational database features such as a parallel SQL query engine and transactions on a highly distributed storage system that scales on standard hardware.
(click to enlarge)
The store is dynamically sharded, supports replication across data centers while keeping transactions consistent, and can deal with data center outages without losing data. The downside of keeping the transactions consistent means F1 has higher write latencies compared to MySQL, so the team restructured the database schemas and redeveloped the applications so the effect of the increased latency is mainly hidden from external users. Because F1 is distributed, Google says it scales easily and can support much higher throughput for batch workloads than a traditional database. The database is sharded by customer, and the applications are optimized using shard awareness. When more power is needed, the database can grow by adding shards. The use of shards in this way has some drawbacks, including the difficulties of rebalancing shards, and the fact you can’t carry out cross-shard transactions or joins.
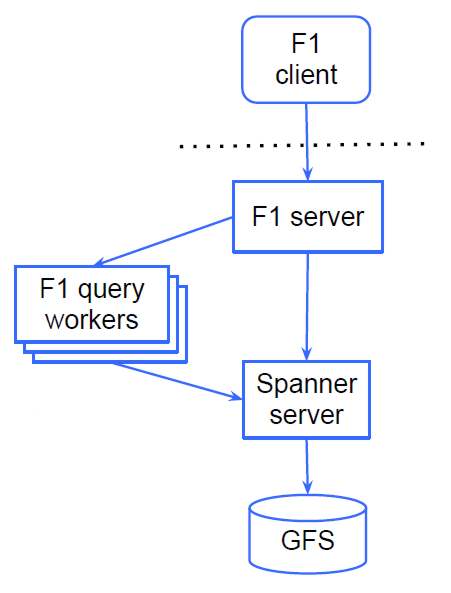
F1 has been co-developed with a new lower-level storage system called Spanner. This is described as a descendant of Google’s Bigtable, and as the successor to Megastore. Megastore is the transactional indexed record manager built by Google on top of its BigTable NoSQL datastore. Spanner offers synchronous cross-datacenter replication (with Paxos, the algorithm for fault tolerant distributed systems). It provides snapshot reads, and does multiple reads followed by a single atomic write to ensure transaction consistency. F1 is based on sharded Spanner servers, and can deal with parallel reads with SQL or Map-Reduce. Google has deployed it using five replicas spread across the country to survive regional disasters. Reads are much slower than MySQL, taking between 5 and 10ms. The SQL parallel query engine was developed from scratch to hide the remote procedure call (RPC) latency and to allow parallel and batch execution. The latency is dealt with by using a single read phase and banning serial reads, though you can carry out asynchronous reads in parallel. Writes are buffered at the client, and sent as one RPC. Object relational mapping calls are also handled carefully to avoid those that are problematic to F1. The research paper on F1, presented at SIGMOD 2012, cites serial reads and for loops that carry out one query per iteration as particular avoidance points, saying that while these hurt performance in all databases, they are disastrous on F1. In view of this, the client library is described as very lightweight ORM - it doesn't really have the "R". It never uses relational or traversal joins, and all objects are loaded explicitly.
More InformationF1 - The Fault-Tolerant Distributed RDBMS Supporting Google's Ad Business (pdf) Related Articles
To be informed about new articles on I Programmer, install the I Programmer Toolbar, subscribe to the RSS feed, follow us on, Twitter, Facebook, Google+ or Linkedin, or sign up for our weekly newsletter.

Comments
or email your comment to: comments@i-programmer.info
|
| Last Updated ( Wednesday, 30 May 2012 ) |