| Machine Learning Speeds TCP |
| Written by Mike James | |||
| Monday, 22 July 2013 | |||
|
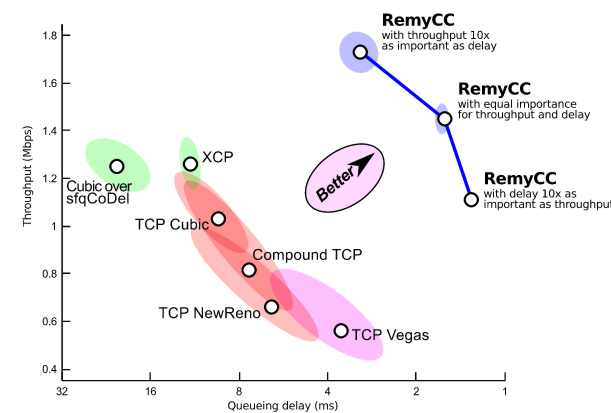
By applying machine learning to the TCP congestion control algorithm, a team at MIT has beaten similar algorithms designed by humans. But don't expect to understand how it works. TCP is the protocol that sits on top of the basic packet switching network to ensure that your data gets through. A packet switching network simply acts as a transport for chunks of data, with no guarantee that the chunks will actually arrive, or if they do arrive that they are in the same order in which they were transmitted. If you want to use a fast, but not reliable method, of transmitting data then you can use UDP but most connections over the internet use TCP. What TCP does is to introduce handshaking to make and break connections. Packets are sent between the source and receiver complete with numbers that indicate the order in which they should be reassembled, and each packet has to be acknowledged. This is a more complicated protocol than you might imagine. For example, how long do you wait for an acknowledgment before you decide to send the packet again? More subtle is the problem of congestion. If you design the TCP algorithm to run as aggressively as possible, i.e. sending and resending data as fast as it can, then the result might be the best possible connection for you, but the rest of the users will tend to suffer a reduced throughput and increased delays because you are hogging the bandwidth. In fact, you could probably get as good a connection by slowing down the rate that you send data so to better match the available bandwidth. This is the problem of TCP congestion control and it is such a complicated problem it is still the subject of ongoing research. Most TCP stacks use one of two congestion prevention algorithms Compound TCP (Windows)or Cubic TCP (Linux), and these methods are only around ten years old. There is clearly still scope for improvement, but are we ready for improvements designed by computer? The MIT team used machine learning to discover the best policy for a decentralized Partially Observable Markov process. Essentially, what the policy amounts to is that each agent either sends or abstains from sending based on a set of observables and the policy attempts to maximize throughput and minimize delays over the whole network, i.e. for all agents. The result is Remy - a computer generated congestion control algorithm - and it seems to work. If you compare it to the existing algorithms then it is clear that it does much better - indeed it occupies a distinct area of the performance graph to the others.
The real problem with this approach is a familiar one in the sense that many AI approaches suffer from the problem of "understandability" or "explainability". A neural network might be able to recognize a cat but we don't really understand exactly, in an engineering sense, how it does it. Expert systems had a similar problem in that they would come to a conclusion, or a diagnosis, but without any reassuring explanation as to why the conclusion had been reached. As the research team comments: "Although the RemyCCs appear to work well on networks whose parameters fall within or near the limits of what they were prepared for — even beating in-network schemes at their own game and even when the design range spans an order of magnitude variation in network parameters — we do not yet understand clearly why they work, other than the observation that they seem to optimize their intended objective well. We have attempted to make algorithms ourselves that surpass So are network engineers willing to trust an algorithm that seems to work but has no explanation as to why it works other than optimizing a specific objective function? As AI becomes increasingly successful the question could also be asked in a wider context.
More InformationTCP ex Machina: Computer-Generated Congestion Control Keith Winstein and Hari Balakrishnan Related ArticlesGoogle Has Another Machine Vision Breakthrough? Google Explains How AI Photo Search Works Deep Learning Finds Your Photos Network Coding Speeds Up Wireless by 1000% Microsoft Wins Award for Infer.NET Bayesian Modeler Google Uses AI To Find Good Tables
To be informed about new articles on I Programmer, install the I Programmer Toolbar, subscribe to the RSS feed, follow us on, Twitter, Facebook, Google+ or Linkedin, or sign up for our weekly newsletter.
Comments
or email your comment to: comments@i-programmer.info

|
|||
| Last Updated ( Monday, 22 July 2013 ) |