| Deep Mind's NoisyNet Suggests Random Is Good |
| Written by Mike James |
| Thursday, 06 July 2017 |
|
We are still at a very early stage in our understanding of Deep Reinforcement Learning and one of the important questions is how to explore the possible range of actions. Some new results from Deep Mind suggest it might be easier than we thought.
It is just over a two years since Deep Mind announced that it had trained a neural network to play Atari games - Google's DeepMind Learns To Play Arcade Games. What was special about the achievement was that the input to the neural network was just the pixels that made up the game and the only guidance the network got was the reward signal generated by winning or losing. Reinforcement Learning is the way most living things learn. We do more of the things that are rewarding and fewer of those things that are less rewarding. Deep Reinforcement Learning is probably going to have the biggest impact of all AI techniques because in this case we don't even have to figure out what the network should do. We don't have to specify its outputs and train it to produce them. All we have to do is let the network engage in the task and apply the rewards that results. The network will devise its own actions to get the biggest reward possible. The only problem is that if the algorithm is to simply move in the direction of the current maximum reward - a so-called greedy algorithm - then the possible range of actions will not be explored and the network will almost certainly end up in a suboptimal state. It will have maximized the rewards obtainable with its initial strategy, but there my well be a much better strategy. Reinforcement Learning researchers have tried all sorts of techniques, mainly involving offering extra rewards for novel behavior, but now Deep Mind's research suggests that a touch of randomness might be all that is needed. This is explained in a new paper by Meire Fortunato, Mohammad Gheshlaghi Azar, Bilal Piot, Jacob Menick,Ian Osband, Alex Graves, Vlad Mnih, Remi Munos, Demis Hassabis, Olivier Pietquin, Charles Blundell and Shane Legg. However, is isn't the randomness of a drunkard's random walk' but something a little more directed. The idea is to use random perturbations in the neural networks weights. This means that the system will explore actions which are close to the actions that are known to be rewarding. A second innovation is using the training method to learn the amount of noise needed. This is typical of Deep Mind's general "everything should be differentiable and hence optimizable" approach.
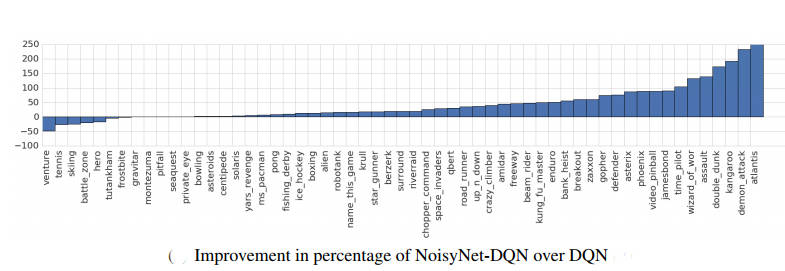
The results are impressive: "We have presented a general method for exploration in deep reinforcement learning that shows significant performance improvements across many Atari games in three different agent architectures. In particular, we observe that in games such as Asterix and Freeway that the standard DQN and A3C perform poorly compared with the human player, NoisyNet-DQN and NoisyNet-A3C achieve super human performance."
More InformationNoisy Networks for Exploration Related ArticlesGoogle's DeepMind Learns To Play Arcade Games Robots Learn To Navigate Pedestrians
To be informed about new articles on I Programmer, sign up for our weekly newsletter, subscribe to the RSS feed and follow us on Twitter, Facebook or Linkedin. 
Comments
or email your comment to: comments@i-programmer.info |
| Last Updated ( Thursday, 06 July 2017 ) |