| Google's DeepMind Learns To Play Arcade Games |
| Written by Mike James | |||
| Tuesday, 03 March 2015 | |||
|
Google has another breakthrough in AI and it's big enough for a paper in Nature - so what exactly is it all about?
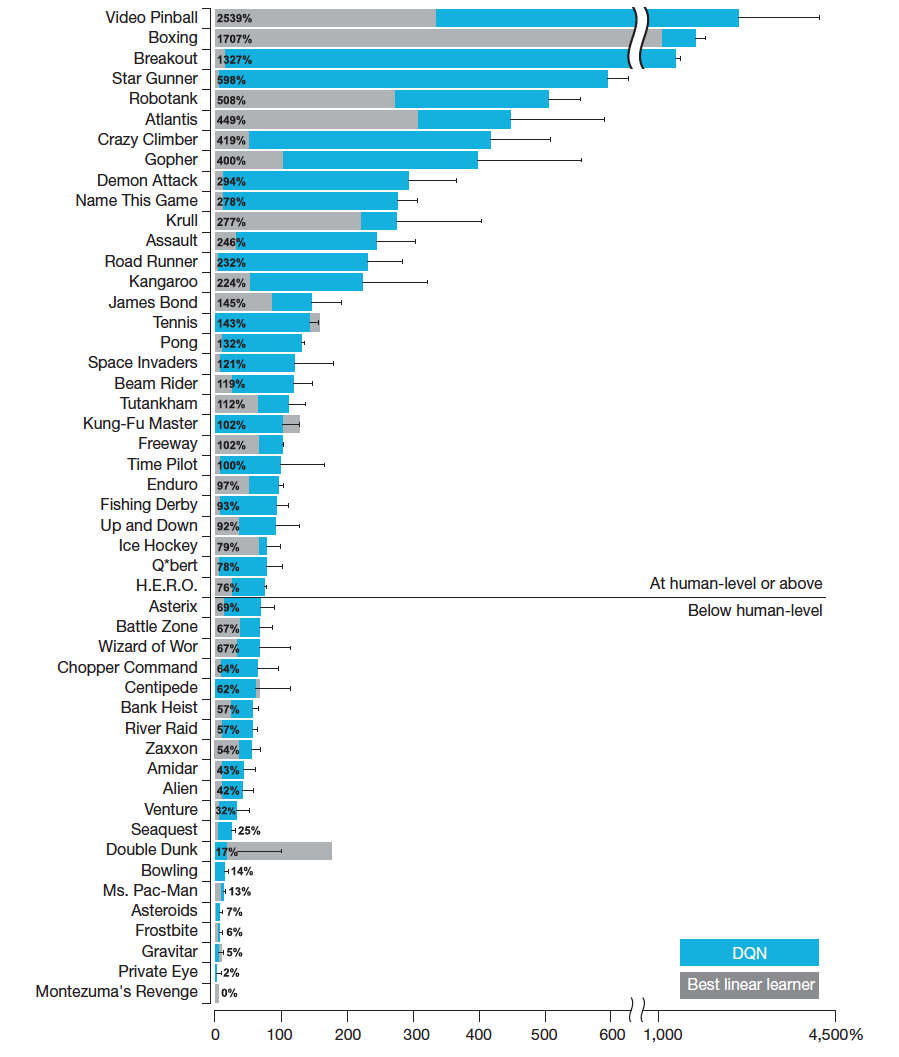
When Google bought DeepMind it seemed to be acting on trust that something good might come out of it. There was a lot of vague talk about AI making great leaps forward with new ways of doing things - the sort of talk that often gets AI a bad name. As it turns out DeepMind has produced at least two good ideas, but they aren't revolutionary. They are simply steps, good steps mind you, down the same road that AI has been on for a while. It won't come as a huge surprise if I tell you now that there is a neural network involved. But the other component - Q Learning might have you rushing to Wikipedia. The crucial fact is that Q Learning is part of the standard canon of reinforcement learning. There are generally said to be three basic types of learning - supervised, unsupervised and reinforcement, but there are shades of grey between all three. The key element in reinforcement learning is that the system does something and instead of being told what it should have done - supervised learning or told nothing at all - unsupervised learning, it gets a reward. The reward can be artificially generated by a supervisor who judges how well the system has done, or it can be a natural part of the task. Animals, including humans, do a lot of reinforcement learning and generally speaking get rewarded if they do the right thing and punished if they do the wrong thing. The way that we usually model reinforcement learning is to have a set of states and actions. The actions move the system from one state to another, usually with some probability, and as a result of the move the system gets a reward - a numerical value. As the system is run slowly it builds up an idea of the value or quality of each action and state and it can then pick actions that maximize its reward. You can see that there are many possible strategies. You could make random actions until you discover the value of every state, this is the explore phase. Then you could use the information to get the biggest rewards - the exploitation phase. However, in most cases it is better to mix the two strategies so that you get maximum reward as quickly as possible. What you need is an estimator of the quality of each action and state and this is what Q learning is. It is an estimate of a state's quality using the current reward and your current knowledge of the estimates of the qualities of all of the states you have visited so far. Now the problem here is that in principle that could be lots and lots of states and you are going to have to keep a very big table of all of the values that you have estimated to date. A better idea is to use a neural network to learn the table and find patterns of states and actions that work. This is what the DeepMind team has done and they connected it to a number of classic arcade games. All the neural network has as an input are the pixels of the screen display. The system can select an action from a set of legal game moves. The only guidance on how to play the game is the feedback it gets via the score, i.e. the score is used as the reward in reinforcement learning. So the neural network combines a Deep Neural Network and Q learning and hence is called a DQN. Applying a DQN to a number of well known arcade games produced a performance that was judged to be better than a professional games tester on a set of 49 games.
The blue bars indicate how good the DQN is compared to an expert human with 100% meaning as good as a human. The grey bars in the diagram show how well a traditional Q-learning program based on a linear function approximator works. One of the unanswered questions is why the DQN failed on tasks where the old linear function approximator works well. The important point is that the same neural network and same training methods were used for all of the games, making the approach seem very general. Of course, the games didn't show much overall variation in type. We have side-scrolling shooters, boxing, 3D car racing, space invaders and breakout, but no games of logic or strategy.
The way that the system discovers seemingly complex strategies is exemplified by the way it learns to knock a hole in the wall in Breakout so that it can gain a high score by bouncing the ball on the back rank. This is fun, but notice that all it has done is to find a set of actions that has a high reward - nothing spooky here. This is a nice piece of work, but it isn't revolutionary as many accounts are styling it. All of the elements of the work have been standard AI techniques for some years. They have even been used together in roughly the same way. What is also interesting is that there are some games where the DQN approach didn't really work very well. What is special about these? My guess is that they all had rewards that didn't connect with the individual actions particularly well, making the credit assignment problem too difficult. Good work - but not a breakthrough yet and far too much hype.
More InformationAs the work is published in Nature you can't read it unless you have a subscription. There is an earlier technical report that you can read however: Playing Atari with Deep Reinforcement Learning DeepMind's Nature Paper and Earlier Related Work From Pixels to Actions: Human-level control through Deep Reinforcement Learning Related ArticlesGoogle Buys Unproven AI Company Deep Learning Researchers To Work For Google Google's Neural Networks See Even Better
To be informed about new articles on I Programmer, install the I Programmer Toolbar, subscribe to the RSS feed, follow us on, Twitter, Facebook, Google+ or Linkedin, or sign up for our weekly newsletter.

Comments
or email your comment to: comments@i-programmer.info
|
|||
| Last Updated ( Tuesday, 03 March 2015 ) |