| Search Engines |
| Written by Administrator | ||||
| Friday, 30 April 2010 | ||||
Page 1 of 3
The web would be virtually unusable without effective search engines that allow us to find the information we want. The web is a vast store of knowledge, currently known to be more than a trillion pages, but it is mostly disorganised and a lot of it isn’t high quality. The task of a modern search engine is not only to help you find relevant material but high quality relevant material. This seems to be a next to impossible task given the difficulty and size of the job, but it’s an essential one if the Internet is to continue to expand in size and usefulness. 
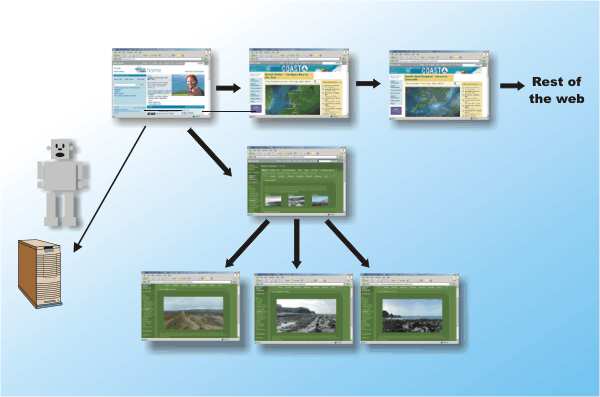
Knowing how it works all can help you get your website more visitors and find the pages you are looking for. Bots, spiders and wormsThe basic method of collecting information about the web is to automate exactly what you do when you “surf the web”. A software robot or “bot” is simply a program that surfs the web by automatically following links from one page to another.
A web bwewot starts at a page and follows all of the links it contains to other pages on the web Notice that a bot doesn’t roam around the web as suggested by its alternative names – spider, crawler, worm or agent – it just sits running on a single machine downloading thousands of web pages. It is very difficult to design an efficient bot that can crawl the web in an effective way. For example, you have to take account of the possibility that a set of pages could contain links to each other that loop round in a circle. The poor bot could end cataloging the same pages over and over again. There is also the small question of getting links to start the search. Most search engines allow website owners to submit their URLs via an on-line form.
A link back to a home page can send a less-than-intelligent bot round in a never ending loop reading the same pages over and over again The index problemA bot downloads pages but what happens next? The bot isn’t intelligent and can’t make sense of the page as you can. Instead the content of the page is used to form an index of words that appear on each page. However most words that appear on a page don’t give you much of a clue as to what it is about. The earliest solution was to use human intelligence to manually build a directory. David Filo and Jerry Yang, two Stanford University students created Yahoo as a development of their own list of favourite sites and it’s still an important search engine. Clearly cataloguing the web manually isn’t going to result in an index that covers very much of its content. Other search engines tried to be clever about which words they used in the index to improve the quality of the automatic catalogue. For example, words that appear in titles are likely to be more important than words that appear in the body text. The search engine Lycos, for example, is said to use words in titles, subheadings and links together with the 100 most frequently used words on the page plus every word in the first 20 lines of text. In an effort to help search engines new HTML tags – meta tags - were introduced with the idea of allowing web page creators to categorise each page. The problem is that meta tags can be used dishonestly to suggest that a page should be returned when it is only trying to sell you something. Today meta tags are only used by bots if they can also verify the information by correlating it with other page content. <ASIN:1857883624> <ASIN:1921573775> <ASIN:0596518862> |
||||
| Last Updated ( Friday, 30 April 2010 ) |