| Search Engines |
| Written by Administrator | ||||
| Friday, 30 April 2010 | ||||
Page 2 of 3
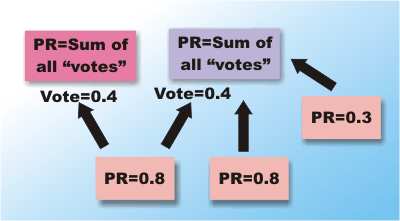
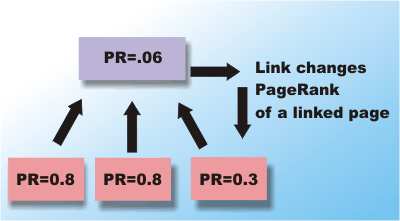
The real breakthrough in search engine design was the PageRank. This was invented by Stanford University students Sergey Brin and Lawrence Page who went on to create Google. PageRank tries to rate the quality and relevance of a page in much the way that a human does. It is an index constructed by looking at the pages that link to the page, i.e. that cite it. The more pages that link to a given page the more important it must be. However PageRank is a little more sophisticated than this because it takes into account the number of other links the citing page makes and its PageRank. You can think of this as the citing page sharing its PageRank out to all the pages it links to. This means that a page can have a high rank either because a small number of high ranking pages link to it or because lots of low ranking pages link to it.
Each page “votes” a proportion of its PageRank to each page it links to – the page’s final rank is the total of all the votes it receives Computing a PageRank isn’t as easy as you might think because it’s an iterative process as pages pass on their current ranking and change their ranking as a result. You can find out exactly how it works in the academic paper that Google’s creators wrote and in the published US patent.
PageRanking is tricky because when a page receives a rank it might change the rank of pages that it is linked to and which link to it Future searchSearch engines are engaged in a war with each other to deliver up exactly the pages you are looking for and with people who try to manipulate them into delivering up the pages that they want highly ranked. Even so, despite the intense competition PageRank or some development based on it is still the best method we have. Over time it has evolved various tricks to make it work better and traps and checks to counter attempts to make pages, that don’t deserve it, rank highly. Because this is a commercial war exact details are hard to come by and secrecy is the main defence. One big problem facing all search engines is “the invisible web” or “deep web”. As the technology used to create the web becomes more sophisticated an increasing number of web pages are being generated dynamically from databases and these are often invisible to bots. Current estimates suggest that the deep web may hold 500 times more information than the visible web. A new generation of bots sometimes called “wrappers” are being designed to search the deep web. A search engine that uses many other search engines to perform a query is also known as a Metasearch engines. The best hope for real improvements in search technology above and beyond the PageRank algorithm is to build increasing intelligence into the user interface so that it aids the search process. Some new search engines are trying to build in an understanding of images and sounds to return web pages with content similar to sketches or music that contains a few specified notes. Currently, however, AI just isn’t good enough to find what you are looking for with anything like human intelligence. The best example of this approach at the moment is Wolfram Alpha. This aims to provide answers to questions using a database of algorithms and language domain engines so it isn't exactly the same as a general search engine. A much better idea is to use personal information to tailor a search. Originall Ask Jeeves and the Amazon search engine A9 keep a history of what you have searched for to suggest additional pages that might be relevant. But the idea was too good not to spread to the main stream search engines and now Google allows uses to specify what they find interesting to automatically make a finer selection from the pages returned. At the end of 2009 Google switch to using personal preferences guided by the sites that they had already visited automatic. That is without asking the Google search engine tends to return results from websites that the user has visited most frequently in the past. This feature can be turned off but most users don't even notice that it is switched on and this can lead to some interesting problems. A similar idea uses geographical information from GPS to suggest local shops and resources that might be of interest. At the moment the whole area of geolocation and customising search by location is a growth area. The big worry with personalised search is privacy. One day soon a search engine might examine every web page you look at, keep a list of everything you purchase and scan your email for clues as to what you are interested in. This same information could also be valuable to anyone wanting to sell you a product or service and would take the search engine advertising into a new realm of profitability. Similarly a location aware search engine could be used, by theives to help target your home while you were else where. The point is that information can be used in ways that were never imagined nor intended. However none of these ideas has produced anything to seriously overtake the original PageRank idea. 
<ASIN:1933988665> <ASIN:0330508121> <ASIN:0557161339> <ASIN:0470226641> |
||||
| Last Updated ( Friday, 30 April 2010 ) |