| Neural Networks |
| Written by Michael James | |||
| Friday, 28 August 2009 | |||
Page 1 of 2 Neural networks are useful and might provide a route to an artificial brain. This article pre-dates I Programmer, having been written in the mid 1980s. From the perspective of 2024 when neural-network based large language models are proving incredibly effective we have come a long way since then. The only examples of intelligence we have are us and the animals that inhabit the planet along with us. If you want to create intelligence, or if you want to make computers even a little more intelligent, then it seems reasonable to look at the way that we and other animals work. However, despite knowing a great deal about the brain and how it is organized, the way that it actually works remains a mystery. It is as if we had a complete design drawing for an engine but still had no idea how it worked. 
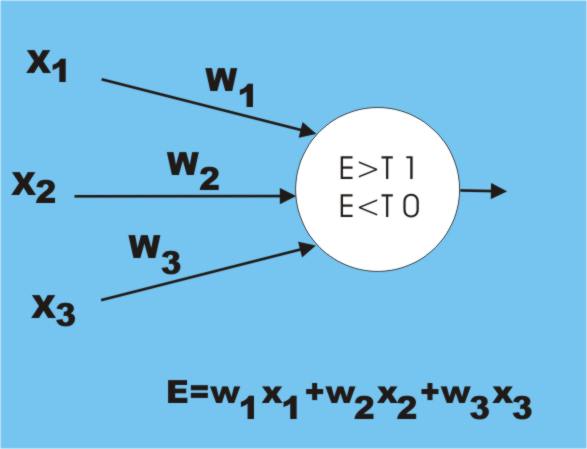
Our state of knowledge of the way that intelligence works is very like the early anatomists who dissected bodies and knew where everything was but didn’t know what the heart, lungs or liver actually did! Slowly, however, we are beginning to make sense of it all. Not as much as some optimistic views would have us believe, but we are at least off the starting blocks. The first real breakthrough was made in 1949 by Donald Hebb, a Canadian psychologist who proposed a general principle of learning. The principle of Hebbian learning is very simple and sadly not well known. A neuron has many input connections to the output of other neurons in a neural network. It “fires” or gives an output that stimulates other neurons when the sum of its inputs goes over a threshold value. Its firing takes the form of a seemingly random burst of pulses. This results in a complex behaviour for the entire network that is very difficult to analyse. Even today we generally have to simulate even quite small networks to discover what their typical behaviour might be. The most general property of brains, which are nothing but huge neural networks, is learning. The question is what magic is responsible for this learning? Hebb suggested that what happened was that any input that was active when the neuron fired was strengthened so that the cell became more sensitive to its input in the future. This unlikely rule really does cause the network to learn and most practical network learning rules can be traced back to it or something related to Hebb’s rule. The idea of a neural network that learns to solve a problem is so attractive you might be surprised to discover that for a long period almost no work was done on the subject. The reason is that in the early days far too much was claimed for the first, very simple, neural networks and when they were proved to be inadequate for the job the bubble burst and the whole approach was discredited. But the early networks were incredibly simple – a single layer of neurons. In fact in many cases the learning was done by a single artificial neuron called a “perceptron”. Of course there were things that a single layer couldn’t learn but extending the network to multiple layers was difficult because no one could work out how to make them learn anything at all! The problem wasn't building multilayer networks it was training them. Training a NeuronBefore we can look at the complete training algorithm we need to look at how a single artificial neuron can be trained. The basic idea is very simple. The neuron has a number of inputs, x1, x2 and so on, and these are combined by multiplying each one by a “weight”, w1, w2 and so on, and adding the results up. You can think of each weight as determining how sensitive the neuron is to the particular input. The output of the neuron is simply some function of the weighted sum of the inputs, usually a threshold which produces an output if the input sums exceed the threshold. You can see how this models the basic idea of a neuron firing only if the input stimulation reaches a suitably high level.
A single neuron How can such a simple device learn anything? First we have to know what we would regard as learning. Suppose we “show” the neuron some inputs that come from one type of object – pixel colour values from photos of a person say – and it fires, but it doesn’t fire when we show it inputs that come from another group of objects. You could say that it recognizes the first type of object and not the second. Of course given a brand new neuron the chances that its weights would be set up so that it fired on the desired set of inputs and not on the other set is quite low. In this context learning is the process of adjusting the weights to make the neuron fire on examples from one group and not fire on examples not from the group. <ASIN:0805843000> <ASIN:0262631113> <ASIN:0671657135> |
|||
| Last Updated ( Monday, 14 October 2024 ) |