| Neural networks |
| Written by Editor | ||||
| Friday, 28 August 2009 | ||||
Page 2 of 3
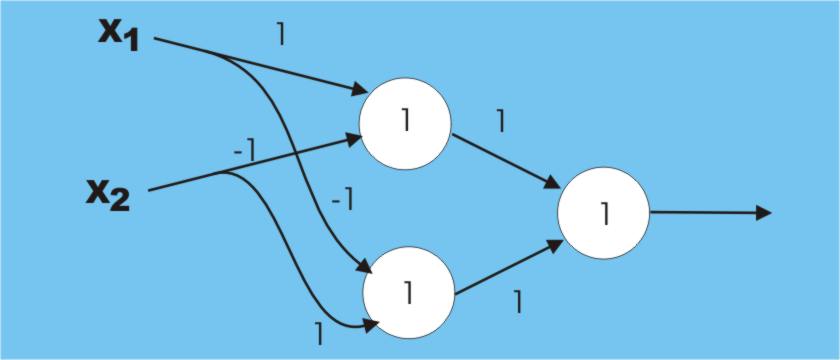
Perceptron algorithmThe first learning algorithm to be discovered solves this particular problem in a very simple way. Start off with a neuron with weights randomly set and present an example from the group that should fire the neuron. Look at the output and if the neuron isn’t firing add xi to the corresponding weight wi – that is add the input value to the current weight for that input. You can see that what this is doing is turning up the sensitivity of each input according to how big the input is and this is what you would expect to try to make the neuron fire. If you then show the neuron an example from the group that it isn’t supposed to recognize you might well discover that it is firing in error. In this case go and subtract xi from wi. You can see that this corresponds to turning the sensitivity to the inputs down, which is again what you would expect to do to a neuron that is firing when it shouldn’t. Finally if the neuron is firing when it should then you can leave the weights alone! This is the perceptron algorithm and the amazing thing is that just by going round and round this procedure the neuron eventually learns to distinguish between the groups. When it was discovered (see the history article on Marvin Minsky) this behaviour was thought to be amazing and, as is the way with all new AI techniques, more was claimed for it than it could deliver. In particular no one noticed that there was an unspoken condition included in the learning algorithm – what was being learned had to be learnable. This seems reasonable because, for example, if you simply give the neuron random inputs for the group you want it to recognize it will never learn to distinguish anything! However, what a neuron can learn is a bit more limited than you might think. For example, if you try to train a neuron using the following simple input: x1 x2 output (that is, you simply want the neuron to recognize a single one on either input) then you will find that it never learns the task. This and many other failures of the single neuron to learn convinced many workers that the whole idea was silly! Looking back it is easy to see what the problem is – why should one neuron be capable of learning everything you throw at it? Clearly, just because you have proved the limitations of a single neuron, you haven’t proved that multiple neurons can go beyond that limitation. In fact it isn’t very difficult to find a three-neuron combination that can solve the 0,1 or 1,0 problem. This was known for a long time but ignored as a proof that there was life in the neuron idea. The reason was that the three-neuron net had to be “hand trained”. That is, its weights were set to values that worked and it didn’t learn them from a repeated presentation of the data. You can see how this works in the figure. Notice that the weights are written alongside the connections and the number inside each neuron is the threshold – the neuron fires is the weighted sum equals or exceeds the threshold. You can also see the input/output table for each neuron. Can you see that the overall input output table for the three neurons is exactly what we need?
Solving the 0,1 or 1,0 problem by hand needs three neurons The big problem is, of course, that unless you have a learning algorithm for neural networks then they are of little use even if they aren’t limited in what they can recognize. The solution, a learning algorithm, was invented a number of times but, because everyone believed that neural nets were a waste of time, it was more or less ignored! The learning algorithm is called “gradient descent” and it is nothing more than an application of some very standard optimisation methods. The basic idea is the same as the one used to adjust the weights of the single neuron, i.e. change the weights so as to make the output move towards the desired value. However, in the case of a neural network you have to work out which weights belong to which neurons and which to adjust. <ASIN:0262650541> <ASIN:0262681080> <ASIN:1841695351> |
||||
| Last Updated ( Saturday, 19 March 2011 ) |