| Can Regular Expressions Be Safely Reused Across Languages? |
| Written by Nikos Vaggalis | ||||||
| Monday, 02 September 2019 | ||||||
Page 2 of 2
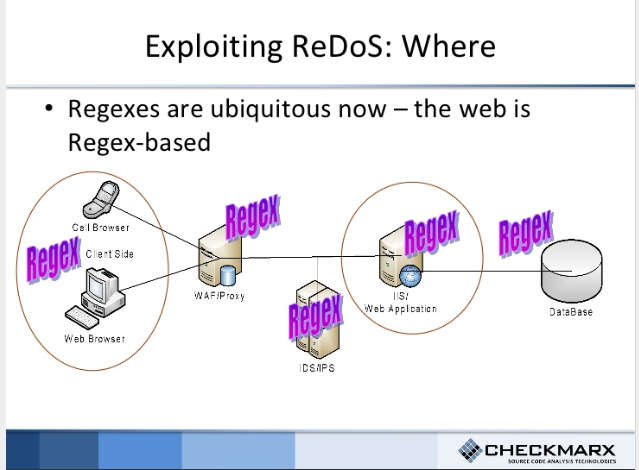
PerformanceThe final part of the report embarks on the issues of performance. Due to differences in the underlying algorithms which the regex engines are based on, a match in some languages may require greater than linear time (polynomial or exponential in the worst case) in the length of the regex and the input string. These are called super-linear matches and some regex engines fall prey to this super-linear behavior while the wiser ones avoid it. It was found that 10% of the regexes exhibit performance differences and that the proportion of regexes that exhibit exponential and polynomial worst case behavior varied widely by language: Within the set of Spencer engines, though, there are distinct Medium and Slow Families. In our experiments, exponential behavior was unusual in PHP and Perl, while it occurs at about the same rates in Java, JavaScript, Python, and Ruby. Similarly, PHP and Perl have a lower incidence of polynomial behavior than do the other Spencer engines. The differences between these two families can be attributed to a mix of defenses and optimizations. So it seems that PHP and Perl, PHP probably because it utilizes the PCRE (Perl Compatible Regular Expressions) library, were the only ones that had explicit defenses against exponential time behavior. Additionally: Perl maintains a cache of visited states in order to short circuit redundant paths through the NFA, permitting it to evaluate some searches in linear time that take polynomial or exponential time in other Spencer engines. As far as polynomial time behavior goes, PHP and Perl again have optimizations that act as a safeguard against that behavior too: For partial matches, some regex engines will try every possible starting offset in the string, trivially leading to polynomial behavior. PHP and Perl have optimizations to prune these starting offsets, and these optimizations appear to reduce the incidence of polynomial behavior in those languages. The relevant optimizations seem to be: (1) skipping ahead to plausible starting points, and (2) filtering out inputs that lack necessary substrings As such, ReDoS-Regular expression Denial of Service, as seen by OWASP : The Regular expression Denial of Service (ReDoS) is a Denial of Service attack, that exploits the fact that most Regular Expression implementations may reach extreme situations that cause them to work very slowly (exponentially related to input size). An attacker can then cause a program using a Regular Expression to enter these extreme situations and then hang for a very long time. must be pretty difficult to pull in those two languages. For a counter example, watch this video by Snyk on ReDos in the popular Javascript npm ms package.
In summing up, the paper manages to dispel the popular myth that regular expressions are portable and with that raise the level of awareness that is necessary for producing error free, secure and efficient code.The message is clear: "If you reuse regexes across language barriers you might potentially open yourself to semantic, performance and security vulnerabilities". That percentage of incompatibility is not negligible; 15% of the languages exhibit semantic differences and 10% exhibit performance differences, despite that most regexes compile across language boundaries . My personal takeaway, the one I have more interest in, is that Perl once again emerges as King, sending shockwaves across to those that were quick to announce it dead pointing out to its declining in popularity. Perl is not just the best tool in the niche of text processing, but it's also the most secure one for developing for the web and its server backends; text filtering, sanitanization and safeguards against exponential matches render attacks such as SQL injection, XSS and ReDoS not trivial to perform. After all, the web IS regex based :
Hold on there's more. In watching SawyerX's presentation at Perlcon Riga 2019 "Perl 5: The past, the present, and one possible future", another powerful feature of the language was revealed; that unlike in most programming languages, regular expressions in Perl are part of the language.They are not just strings that you send to a function, as such they are checked at compile time.That is closely related to the misinterpretation that Perl is a purely interpreted language.Well it is but there's also a compile phase which does optimizations and pulls some magic:
So if there's a syntax error with your regex, it will be caught at compile time and not blow at run time as happens with SQL.Therefore you catch the error in development and not when the code ships to the user. The moral of the story is that the next time you feel the urge to copy a regular expression, or generate one in your favorite online playground, make an effort to think it through and test it out before you go on pasting it!
More Information
Related ArticlesParsing with Perl 6 Regexes and Grammars Advanced Perl Regular Expressions - The Pattern Code Expression Advanced Perl Regular Expressions - Extended Constructs Machine Learning Lab's Regular Expression Game Automatically Generating Regular Expressions with Genetic Programming
To be informed about new articles on I Programmer, sign up for our weekly newsletter, subscribe to the RSS feed and follow us on Twitter, Facebook or Linkedin.

Comments
or email your comment to: comments@i-programmer.info
<ASIN:1484232275> |
||||||
| Last Updated ( Tuesday, 03 September 2019 ) |