| Exploring Edison - Fast Memory Mapped I/O |
| Written by Harry Fairhead | |||||
| Wednesday, 23 September 2015 | |||||
Page 2 of 4
Fast Mapped I/OThe most recent versions of mraa support another way to access the GPIO and it is much faster. Most of the delay in setting the GPIO line is due to mraa using the Linux SYSFS subsystem. SYSFS is a file system that can be used for all sorts of interfacing tasks. In this case SYSFS is being used to map the GPIO pins as if they were files in a file system. This has the advantage of making the GPIO available to almost anything that runs under Linux, but has the disadvantage of a high overhead. A faster way to work with the GPIO lines is to allow the software to write directly to the memory locations where the GPIO port registers live. This is a standard part of the SYSFS facility and there is a special file that memory maps the driver so writing to a particular address sets a given line high and to another address sets it low. Notice that using memory mapped I/O only changes the way the line is read or written. For all other operations such as setting the line's direction a SYSFS call is used. The installation of the memory map is something mraa can do and it will substitute memory mapped read and write function for any given pin. The addresses and data masks are computed from scratch each time and there is a slight speed up to be gained by precomputing them and providing your own read/write functions for each pin. However the gains are hardly worth it - see later. You can set how any pin is accessed using the function:
If the second parameter is 1 then the pin is accessed directly i.e. a fast memory mapped access. If the parameter is 0 the slower SYSFS interface is used. Changing the program to use fast I/O on pin 31:
Putting this another way the SYSFS approach can produce a 0.03 Mhz pulse train but memory mapping can produce a (close to) 2Mhz pulse train. Of course we still have the problem that the program is running under a non- realtime operating system and therefore it will be interrupted and there will be jitter in the faster pulse train as well. The next step is to create pulses longer than 0.25 microseconds. There isn't much point in trying to use usleep because the overhead in yielding to the operating system is such that usleep(1) produces 98 microsecond pulse. In other words using usleep with fast memory map access produces pulses in the same sort of region as you can create using slow SYSFS. If you want to use usleep with fast memory mapped mraa you can use the following formula to work the delay. If you want a pulse of width t microseconds delay for :
microseconds in usleep. This is accurate from 100 to 800 microseconds. If you want to generate pulses in the range 0.25 to 100 microsecond range then you have little option but to busy wait.
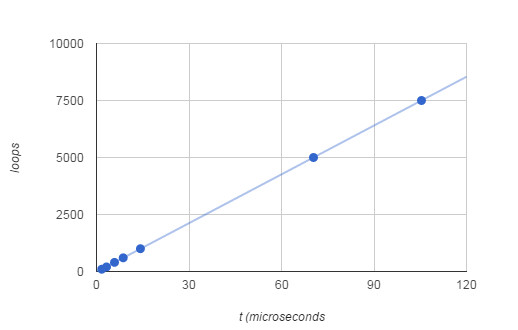
The relationship between loop counter and pulse length is linear up to at least 100 microseconds.
The formula for the number of loops needed to create a pulse of length t is:
So for a 10 microsecond pulse you need 692 loops. Not perfect, but a good start for manual trimming. In short using fast memory mapped output and busy wait you can generate reasonably accurate 1 to 10 microsecond pulses. Notice that this doesn't mean we are home and dry when it comes to fast output. If you try to change multiple lines within a loop then the time for each loop increases and there will be phase shifts between the pulses generated. For example if you try:
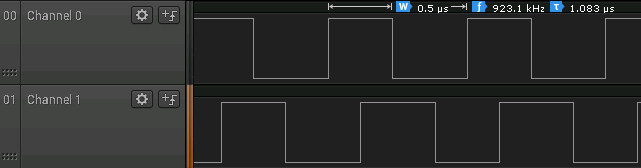
Notice however that each pulse is 0.5 microseconds and the overlap is for a much shorter time - approximately 0.25 microsecond. However the comparison isn't completely fair. If you generate memory mapped pulses of the same sort of length as the SYSFS approach works with then things look a lot better:
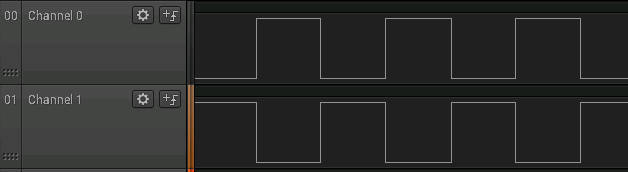
Now it does look as if the pulse trains are out of phase and the overlap is smaller. The point is that memory mapping is not just for short pulse durations but for more accurate pulse generation. Without a register based access to the GPIO which would allow you to set multiple pin outs in one operation this is about as good as it gets.
<ASIN:B00ND1KH42@COM> <ASIN:B00ND1KNXM> <ASIN:B00ND1KH10> |
|||||
| Last Updated ( Tuesday, 10 May 2016 ) |