| Deep C# - Value And Reference |
| Written by Mike James | ||||
| Monday, 04 October 2021 | ||||
Page 2 of 3
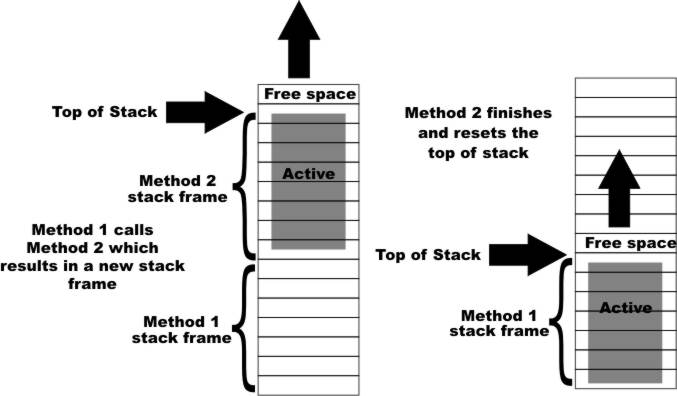
The beauty of stack allocation is that to implement garbage disposal all that has to happen is that when each method terminates it simply clears the stack of its stack frame, i.e. it adjusts the stack pointer to point to the end of its stack frame, so returning the memory to use. Of course, when a method ends, control returns to the method that called it and it finds the stack in just the state it needs to access its own local variables.
The stack in action
The stack works well for storing all manner of data that is created and destroyed following the pattern of method calls, but for global data and for very large or complex data we need something else. The alternative is the "heap". This is a very descriptive name for an area of memory that is set aside simply for the purpose of storing global data. When a global object is created, by the use of This the general idea of heap management, but in practice there are many subtle problems. For example, as the heap is used and released, it slowly becomes fragmented into small blocks of heap in use separating blocks of free space. The solution is to make the garbage collector consolidate memory every now and again. It is generally better to adopt a throwaway approach to heap management. For example, if an object, a string say, needs to increase in size then, rather than try to open up some space to make the current allocation bigger, it is generally better to mark the current allocation as garbage ready for collection and allocate a whole new block of memory, even though this involves copying the existing object. This strange fact, that it is faster to create new storage rather than extend the existing, leads on to other ideas. For example, in most languages, including C#, strings are immutable. That is, once defined you cannot change a string. All you can do is apply operations that make new strings. You can think of immutability as a high-level concept motivated by philosophical considerations or just a good idea given the way storage allocation and deallocation behaves. Storage on the stack fits in with the idea of local variables and the call and return pattern of methods. Storage on the heap gives rise to objects that are regarded as global, but with local references to them. When all of the references to an object are destroyed the object is no longer of any use and may be garbage collected. 
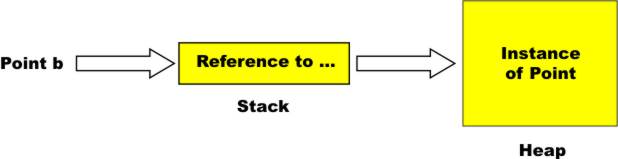
Thinking About ReferencesWhat you should have in mind is the idea that a value type stores its value and a reference type stores a “pointer” to its value. Consider:
In contrast, if you declare a reference type, e.g. a you can then create a reference variable of the same type:
This declares a reference type
This way of thinking has a nice tidy symmetry, even if it is spoiled by C#'s insistence on not letting you access an undefined variable - which is very reasonable. To create a
Now we have a
Notice that the reference variable b is just like the value variable a in that they are both stored on the stack and both store immediate values - the difference is that a’s value is the data and b’s value is a reference to the data. Of course we often combine these two steps together to create the familiar idiom:
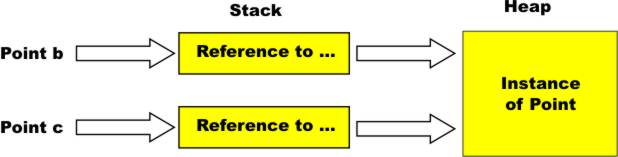
This often seems to the beginner as redundant because of the way it uses “Point” twice. The first use of Point declares a reference to a point object, i.e. b, and the “new Point” part actually creates the point object. It doesn’t take long for this to seem so familiar that you don’t give it a second thought. Another important difference is that an object can correspond to multiple reference variables. For example:
This creates a single Point object but two reference variables both of which “point” at the same object.
|
||||
| Last Updated ( Monday, 04 October 2021 ) |