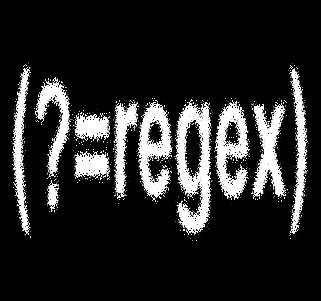| .NET Regular Expressions In Depth |
| Written by Mike James | ||||||
| Thursday, 16 July 2020 | ||||||
Page 3 of 5

Capture and backreferenceNow that we have explored grouping it is time to introduce the most sophisticated and useful aspect of regular expressions – the idea of “capture”. You may think that brackets are just about grouping together items that should be matched as a group, but there is more. A subexpression, i.e. something between brackets, is said to be “captured” if it matches and captured expressions are remembered by the engine during the match. Notice that a capture can occur before the entire expression has finished matching – indeed a capture can occur even if the entire expression eventually fails to match at all. The .NET regular expression classes make captures available via the capture property and the CaptureCollection. Each capture group, i.e. each sub-expression surrounded by brackets, can be associated with one or more captured string. To be clear, the expression:
has two capture groups which by default are numbered from left-to-right with capture group 1 being the (<div>) and capture group 2 being the (</div>). The entire expression can be regarded as capture group 0 as its results are returned first by the .NET framework. If we try out this expression on a suitable string and get the GroupCollection result of the match using the Groups property:
Then, in this case, we have three capture groups – the entire expression returned as Grps[0], the first bracket i.e. capture group 1 is returned as Grps[1] and the final bracket i.e. capture group 2 as Grps[2]. The first group, i.e. the entire expression, is reported as matching only once at the start of the test string – after all we only asked for the first match. Getting the first capture group and displaying its one and only capture demonstrates this:
which displays 0 11 <div></div> corresponding to the first match of the complete expression. The second capture group was similarly only captured once at the first <div> and:
displays 0 5 <div> to indicate that it was captured by the first <div> in the string. The final capture group was also only captured once by the final </div> and:
displays 5 6 </div>. Now consider the same argument over again but this time with the expression:
In this case there are four capture groups including the entire expression. Capture group 0 is the expression ((<div>)(</div>))* and this is captured once starting at 0 matching the entire string of three repeats, i.e. length 33. The next capture group is the first, i.e. outer, bracket ((<div>)(</div>)) and it is captured three times, corresponding to the three repeats. If you try
you will find the captures are at 0, 11 and 22. The two remaining captures correspond to the <div> at 0, 11 and 22 and the </div> at 5, 16 and 27. Notice that a capture is stored each time the bracket contents match.
Advanced captureThere other capture group constructs but these are far less useful and, because they are even more subtle, have a reputation for introducing bugs. The balancing group is, however, worth knowing about as it gives you the power to balance brackets and other constructs but first we need to know about a few of the other less common groupings – the assertions. There are four of these and the final three are fairly obvious variations on the first. They all serve to impose a condition on the match without affecting what is captured Zero-width positive lookahead assertion
This continues the match only if the regex matches on the immediate right of the current position but doesn’t capture the regex or backtrack if it fails. For example,
only matches a word ending in a digit but the digit is not included in the match. That is it matches Paris9 but returns Paris as capture 0. In other words, you can use it to assert a pattern that must follow a matched subexpression. Zero-width negative lookahead assertion
This works like the positive lookahead assertion but the regex has to fail to match on the immediate right. For example:
only matches a word that doesn’t have a trailing digit. Zero-width positive lookbehind assertion
Again this works like the positive lookahead assertion but it the regex has to match on the immediate left. For example:
only matches a word that has a leading digit. Zero-width negative lookbehind assertion.
This is just the negation of the Zero-width positive lookbehind assertion. For example:
only matches a word that doesn’t have a leading digit. Now that we have seen the assertions we can move on to consider the balancing group:
This works by deleting the current capture from the capture collection for name2 and storing everything since the last capture in the capture collection for name1. If there is no current capture for name2 then backtracking occurs and if this doesn’t succeed the expression fails.
|
||||||
| Last Updated ( Thursday, 16 July 2020 ) |