| Applying C - Floating Point |
| Written by Harry Fairhead | |||||||||||||||||
| Tuesday, 21 May 2024 | |||||||||||||||||
Page 2 of 4
Floating Point AlgorithmsAlgorithms for working with floating point numbers are complex and very easy to get wrong. For example, consider the algorithm for adding two floating point numbers. You can’t simply add the fractional parts because the numbers could be very different in size. The first task is to shift the fraction with the smallest exponent to the right to make the two exponents equal. When this has been done the fractional parts can be added in the usual way and the result can then be normalized so that the fraction is just less than 1. This sounds innocent enough, but consider what happens when you try to add 1 x 2-8 to 1 x 28 using an eight-bit fractional part. Both numbers are represented in floating point as 0.1, but with exponents of 2-7 and 29 respectively. When you try to add these two values the first has to be shifted to the right nine times, with the result that the single non-zero bit finally falls off the end and the result is zero in the standard precision. So when you think you are adding a small value to 1 x 28 you are in fact adding zero. int main(int argc, char** argv) {
float v = 0.999999F;
do {
v = v + 0.0000001F;
} while (v < 1);
return (EXIT_SUCCESS);
}
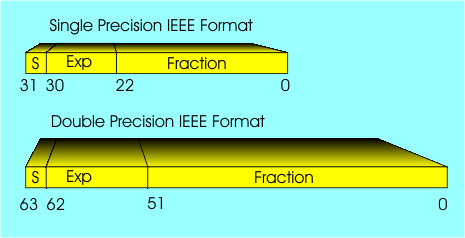
This program does complete the loop, but if you add one more 0 before the 1 in the quantity added to v, the loop never ends. Notice that because of the use of IEEE standard floating point this behavior is almost machine-independent. Floating point arithmetic can be dangerous! Be aware that adding or subtracting values of very different sizes can be the same as adding or subtracting zero. IEEE standard – Single & DoubleTo try to make it safer, there is a standard for floating point arithmetic, the IEEE standard, which is used by nearly all floating point hardware, including all flavors of Intel-derived hardware since the Pentium was introduced. It applies to the ARM range of processors and most DSPs (digital signal processors) that have floating point. Single precision IEEE numbers, floats in C, are 32 bits long and use one sign bit, an 8-bit exponent with a bias of 127, and a 23-bit fraction with the first bit a 1 by default. This gives 24 bits, or 7.22 decimal digits, of precision. You should now see why the loop listed above fails to operate at exactly seven zeros before the 1. Double precision IEEE numbers, doubles in C, are 64 bits long and have one sign bit, and an 11-bit exponent with a bias of 1023. This provides nearly 16 decimal digits of precision. There are other IEEE standard formats for floating point, but these two are the ones you are most likely to encounter.
IEEE standard floating point formats used inside nearly every modern machine. If you need to choose between single and double precision, it is worth knowing that, for a modern FPU, double precision floating point addition and multiplication take about the same time as single precision floating point, but double precision division is often slower by a factor of 1.5 or more. The other issue is that, whereas single precision takes four bytes, double requires eight bytes. In chapter but not in this extract:
Special Values – NaN and InfNow we come to another controversial and much misunderstood aspect of IEEE floating point arithmetic – the special values NaN (Not a Number) and inf (infinity). These two special values are represented by bit patterns that cannot occur in normal floating point. The NaN and inf special values are related and this is often not understood. The operations that can produce NaN are:
inf is the result of an operation that produces an overflow. For example, FLT_MAX *2 evaluates to inf and -FLT_MAX *2 gives -inf. At this point you are probably thinking that this isn’t a good idea. When something like NaN or inf occurs in an expression then the system should generate an error and the program should either handle the error or terminate. The intention of the IEEE standard is to allow a complex expression to continue to be evaluated and produce a reasonable result. It is easy to see how NaN and inf are generated, but how do they allow the expression evaluation to continue. The situation with NaN is very simple - the whole expression evaluates to NaN which you can test for. For example: float w;
w = 0.0/0.0;
printf("%f \n",w);
prints -nan. The problem with testing for NaN is that there is no machine- or compiler-independent way of doing the job. This is because the representation of NaN is not specified and there can be more than one. For example, a single precision float representation of NaN is: s111 1111 1xxx xxxx xxxx xxxx xxxx xxxx where s is the sign bit and the x sequence is non-zero and can be used to encode additional information, the payload, which is usually ignored. If the bits are 0 then this is a representation of a signed infinity. That is:
and the first value that can be used as NaN is: As w = 0.0/0.0;
printf("%d \n",isnan(w));
printf("%d \n",w == w);
prints More of a problem is inf. This is a value that allows an expression to continue to be evaluated and in some cases it can disappear to produce a final expression that looks as if nothing has gone wrong. For example: float w = 3/(1.0/0.0);
printf("%f \n",w);
If you were asked what the above expression printed, most likely you would guess that it was an error as you would properly regard the 1.0/0.0 is either undefined or infinity. In fact using IEEE floating point the result is 0.0. If you rewrite the expression as: float w = 3*0.0/1; then the answer 0.0 isn’t so unexpected. To be clear, in math division by zero using integers, rationals, reals or complex numbers is undefined and there is no room for argument. Given a/0 there is no number of any sort that multiplies 0 to give a. However, programming isn’t math and we are free to use a pragmatic interpretation of division by zero and many other operations. The idea is that we assume continuity of operations and assign a value to expressions such as a/0, the value in the limit of a/b, as b is reduced to 0. Clearly in this case the result gets bigger and bigger as b gets smaller and smaller. Hence we are being reasonable when we assign infinity to a/0. Notice that if a is negative then we have -inf. However, as IEEE floating point has a +0 and a -0, we also have In this case the sign of the zero is taken as indicating the side that the limit is taken from, +0 implies a positive value getting smaller and -0 is a negative quantity getting smaller. What this means is if you change the last example to: w = 3/(1.0/-0.0); then you will see -0.0 printed. Things can go wrong as the limit isn’t defined in all cases. Consider inf/inf and 0/0. In both cases the answer depends on how the limit is reached and you can produce any answer you like by a careful choice. In these cases the result is NaN. You can think of IEEE floating point as being arithmetic with limiting arguments used to produce unique results for otherwise undefined operations and NaN where there is no such unique result. Finally, while positive and negative zero determine the “side” the limit is taken, it is still true that +0 == -0 However, as +inf! = -inf, x == y does not imply 1/x == 1/y as it fails for +0 and -0. |
|||||||||||||||||
| Last Updated ( Tuesday, 21 May 2024 ) |