| Processing XML documentation |
| Written by Mike James | ||||
| Tuesday, 21 December 2010 | ||||
Page 2 of 3

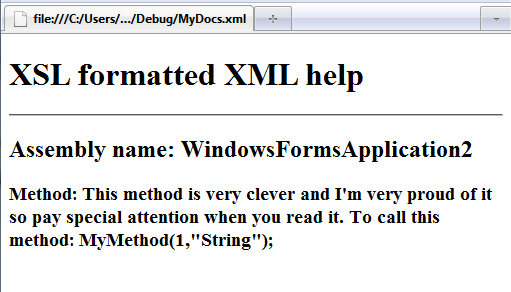
Slightly more complicated is retrieving the summary text corresponding to MyMethod: <h3> In this case the XPath statement is complicated because of the need to quote the entire name of the member – but that’s all. The form of the selector just picks out all of the member tags but the predicate that follows narrows this selection down to the one with a name attribute equal to the quoted string. Finally we bring the web page to a close: </body> If you now load the original XML file into a browser that supports XSL, i.e. any modern browser, it will be transformed by the XSL file assuming they are both stored in the same directory. The complete listing of the XSL file is: <?xml version="1.0"?> The result can be seen below:
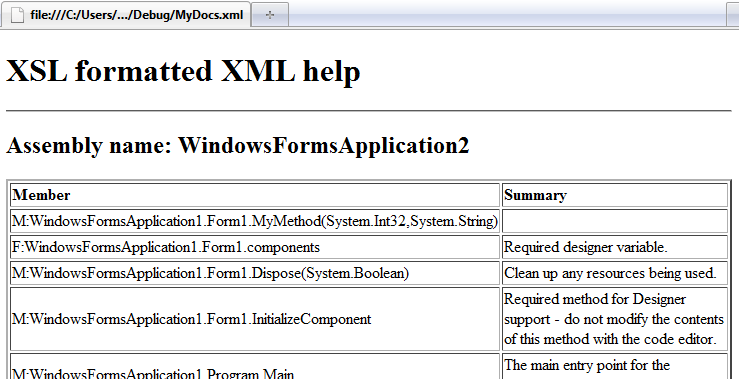
XSL LoopsOf course in a real application you wouldn’t be quoting the name of each member in the way described above unless it was a very special member that needed individual attention. What is needed is some sort of automatic processing of each class and each method to generate documentation in a standard format. The good news is that XLS has the basic facilities of a processing language. In most cases members would be processed using an XLS for loop something like: <table border="2"> In this case additional HTML has been supplied to build a table of members and names but the same sort of general technique can be used to construct other presentations. Notice the way that the for-each construct repeats for each node in the selected set and notice that within the loop the XSL XPath selections start from the currently selected node in the for loop. The overall result of the XSL transformation can be seen below
<ASIN:0596007647> |
||||
| Last Updated ( Tuesday, 21 December 2010 ) |