| How To Successfully Teach Computing Disciplines To The Uninitiated |
| Written by Nikos Vaggalis | |||
| Monday, 18 February 2019 | |||
Page 1 of 2 How can you turn a student with little background in computation into a competent programming computer user? Could the solution be R and data science. This topic is addressed in a research paper on how SciNet, the supercomputer department of the University of Toronto, teaches Computing Disciplines to graduate students in emerging computational fields such as biology and medical science.
Toronto University specifics aside, the research paper contains valuable insight on how to construct a successful course on just about any subject in general.SciNet despite not a teaching department but rather a research consortium, offers this course to the University's students in partnership with other University departments such as the Institute of Medical Science, the Physics Department or the Department of Physical and Environmental Sciences.
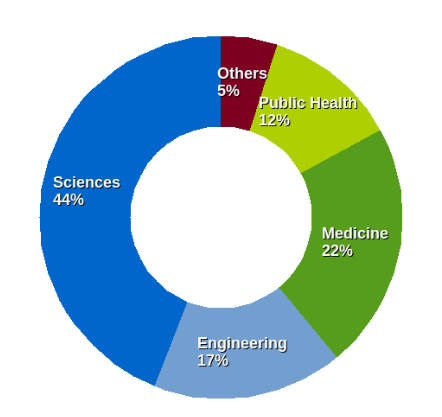
Distribution of student’s departments/institutions in all SciNet courses, period 2013-2017 Its challenge is to bring students without a background on CS up to speed with coding and software development practices and render them able to perform computational and statistical analysis as well as machine learning on data that pertain to their field of science, in accordance with the trend that nowdays working with data is just about everywhere. Examples are, clinical trials, drug tests, medical cases, hospital treatments, differential gene expressions, and more. For example, Biomedical computation typically involves statistics, data analysis and knowledge in interpreted languages. The course begins by offering an introduction to the R programming language and statistical analysis's basic concepts with theory and practice going hand in hand as statistical methods such as hypothesis testing, parametric, non-parametric model creation, model diagnosis, clustering and decision trees algorithms are both discussed but also applied to real world examples using R. In detail the curriculum is comprised of :
The course lasts for twelve weeks with two 1-hour lectures per week, while grading is based on 10 assignments whose average makes up the final grade. One of the reasons that the course has become such a success arises from the fact that attendance is not mandatory since the lectures and their material are delivered in such a way that gives students the flexibility of attending in person or watching remotely. Secondly, rather than basing and working on some predetermined data samples that potentially mean nothing to the student, the educators encourage to bring your own data to the table. This way students can apply the techniques and tools presented in a way that is meaningful to their own research field hence achieving immediate feedback as they are basically work on their own research questions and problems.This though poses the issue that grading cannot be done quantitatively as there aren't standard solutions to the handed out homework since the data that it is based upon is custom.This issue is sidestepped by providing very detailed guidelines on the things to look for when grading. Another ingredient to the successful recipe as well as particularly invaluable in classes with a great number of students, is to delegate grading to TAs or Teaching Assistants, a practice also employed by popular MOOCs. Thanks to TAs the luxury of looking at each student assignment individually and not in bulk can be afforded.Therefore each assignment is checked against the logic of the implementation and not just the outcome, while students also receive individual feedback and detailed comments on it. TAs are often students who have taken the course before, therefore are already trained on the best practices, philosophy and requirements the course is after.Hence their experience can be leveraged in helping new students by anticipating their needs.This is a scheme also employed by Udacity's Nanodegrees as qualified graduates are promoted to the positions of "Mentors". Depending on the subject at hand, more practice or more theory is offered. For example, when covering topics such as introduction to Linux Shell, exploring the basics of the R language, visualization, etc, a more practical outlook is employed. However, if the topic to be covered requires some theoretical background, we then deliver a more traditional lecture – e.g. reviews on probability and statistics, introduction to machine learning and neural networks, etc Whatever the case, computer use is required in order for the students to actively follow the material's computational implementation.It is preferable for the students to carry their own laptop than to work on the standard pc's of the computer lab.That way they feel more comfortable because they work on their own machines, while at the same time gaining much needed practice in setting up the environment and tools on their own. But the computer lab is not preferred for one more reason.The ideal location of running the lectures is the traditional lecture rooms due to their plentiful space which allows both students and lecturers to comfortably use their own laptops as well as move easily around, something especially desired for lectures that contain hands-on components. |
|||
| Last Updated ( Monday, 18 February 2019 ) |