The current research, reported in "37 Million Compilations: Investigating Novice Programming Mistakes in Large-Scale Student Data" aimed to go even further than its predecessor by providing a more detailed investigation into the characteristics of the mistakes, trying to answer the following research questions:
What are the most frequent mistakes in a large-scale multi-institution data set?
What are the most common errors, and common classes of errors?
Which errors take the shortest or longest time to fix?
How do these errors evolve during the academic terms and academic year?
To arrive at valuable conclusions, a large data set should exist, and Blackbox had exactly that: participation of 250,000 Java programming novices from institutions all over the world and source code from 37 million compilations.
In more detail, the research used the data collected during the 2013-2014 academic school year, a total of 37,158,094 compilation events, of which 19,476,087 were successful and 17,682,007 were unsuccessful. The analysis of the data was done in Haskell.
After processing that huge amount of data, the list with the most frequent mistakes was compiled (in descending order, thus error C is the most frequent) :
Unbalanced parentheses, curly braces, brackets, and quotation marks, or using these different symbols interchangeably, such as in: while (a == 0].
Invoking methods with wrong arguments or argument types, such as in: list.get("abc").
Control flow can reach end of non-void method without returning, such as in:
public int foo(int x)
{
if (x < 0)
return 0;
x += 1;
}
Confusing the assignment operator (=) with the comparison operator (==), such as in: if (a = b).
Ignoring or discarding the return value of a method with non-void return type, such as in: myObject.toString();.
Use of == instead of .equals to compare strings.
Trying to invoke a non-static method as if it was static, such as in: MyClass.toString();.
Class claims to implement an interface, but does not implement all the required methods, such as in: class Y implements ActionListener { }.
Invoking the types of parameters when invoking a method, such as in: myObject.foo(int x, String s);.
Incorrect semicolon in if statements or for and while loops, such as in: if (a==b); return 6;.
But that's not all. Further insights conclude that:
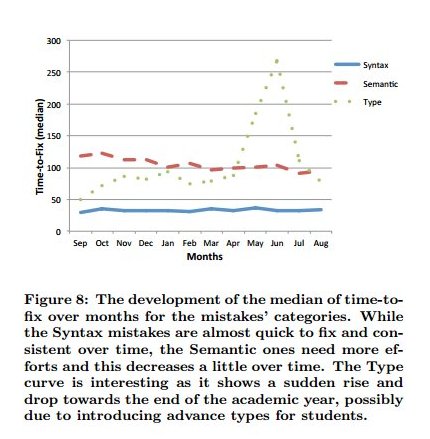
"Syntax errors show a small peak at the beginning of the northern hemisphere academic year, but otherwise are fairly flat. In the contrast, the slight peaks for the Semantic and Type categories happen later. We propose that this is due to the order of topics in academic courses: students initially struggle with syntax, but as they master this, they begin to grapple instead with semantic and type errors. ..... While the Syntax mistakes are almost quick to fix and consistent over time, the Semantic ones need more efforts and this decreases a little over time.
The Type curve is interesting as it shows a sudden rise and drop towards the end of the academic year, possibly due to introducing advance types for students. The Time-to-fix of Syntax mistakes is almost flat, showing that they are quick to fix, but students do not generally get faster at fixing them.
In contrast, Semantic mistakes show a decrease of the time needed to fix over the course of the year, Type mistakes show a strange, unexpected shape.
The only interpretation we can offer is that with the increase of topics introduced to students, moving from primitive types to generic types and inheritance, students tend to make more mistakes between these ‘more diffcult’ types"
So as a side-product of the research's findings, can we reach a conclusion as far as typing is concerned? Are dynamic languages easier to work with, since they require no type information at compile time as automatic type coercion is done at runtime?
In other words, is dynamic typing better since you avoid the Type related mistakes from happening?
It certainly sounds so. Further proof comes from another study, "An Empirical Investigation into Programming Language Syntax".
Its findings were that :
"Our results may also have implications for instructors and students in regards to the use of static type systems, because of the observed difficulty novices have with static type annotations. novices only placed type annotations approximately half the time in our study, across tasks and languages. From a language design perspective, computer code inside of a method can probably remove type annotations under many conditions while still maintaining static typing. However, for method declarations, there may be an unresolvable trade-off between static and dynamically typed languages."
At first it might appear that dynamic typing helps novices but further down we find that :
"We suspect that some might believe our results imply dynamic typing is better for novices, but we find this explanation implausible.....Thus, claiming that dynamic typing is better for novices is incorrect without the proper context. "
Instead a system utilizing type inference is the way to go :
"We have derived a type inference system that removes most type annotations inside of methods, keeps annotations in method declarations, and keeps static type checking itself. More study is needed, but compromises like this may afford ease of use for all."
All these conclusions are a product of data collection done through a single IDE. Imagine an initiative that collected data from the many hundreds of MOOC's out there. How would that improve the experience of programming and evolve educational material?
Utilization of such data in the educational industry would lead to big gains almost from day one.
LeetGPU is a platform where you can write and test CUDA code. Now it adds Challenges to foster competition, asking you to put your GPU programming skills to the test by writing the fastest program [ ... ]
Microsoft has announced the second preview release of .NET 10 with enhancements across the .NET Runtime, SDK, libraries, C#, ASP.NET Core, Blazor, and .NET MAUI.