| Google Showcases F1 |
| Written by Kay Ewbank | |||
| Tuesday, 03 September 2013 | |||
|
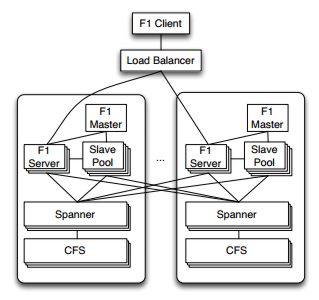
Google has released details of the hybrid database appropriately named F1 that has replaced MySQL in the company’s Adwords platform. Google Adwords is a massive system involving hundreds of applications, thousands of users, all using a shared database over 100TB in size. In a presentation at the Very Large Database Conference (VLDB), Google said that the users generate hundreds of thousands of requests per second, and that the database runs SQL queries that scan tens of trillions of data rows per day. As explained when we originally reported on it, F1 is a hybrid database that combines high availability, the scalability of NoSQL systems like Bigtable, and the consistency and usability of traditional SQL databases. F1 is built on Spanner, Google’s database that is the largest single database on earth. Spanner is designed to be scaled across millions of servers, and stretches across the world while appearing as a single entity. The Spanner storage and computation system spans all Google’s data centers. F1 was developed at the same time as F1, and in close collaboration. Spanner handles lower-level storage issues like persistence, caching, replication, fault tolerance, data sharding and movement, location lookups, and transactions.
The use of Spanner gives F1 synchronous cross-datacenter replication and strong consistency. In its paper on F1 given at the VLDB conference, the Google team of researchers says that synchronous replication implies higher commit latency, but this can partially be overcome by using a hierarchical schema model with structured data types. F1 also includes a fully functional distributed SQL query engine and automatic change tracking and publishing. F1 is fault-tolerant, globally-distributed and supports both OLTP and OLAP. It was designed to replace a sharded MySQL implementation that wasn’t keeping up with Google’s needs in terms of scalability and reliability. The paper says that the sharded database based on MySQL was hard to scale up, and even more difficult to rebalance. Users needed complex queries and joins, which meant they had to carefully shard their data, and resharding data without breaking applications was challenging. F1's design goals are to be scalable trivially and transparently, just by adding resources. In terms of availability the system must never go down for any reason: the system stores data for Google's core business, and any downtime has a significant impact on revenue. Consistency is the third goal; F1 has to support ACID transactions, and must always present applications with consistent and correct data. “Designing applications to cope with concurrency anomalies in their data is very error-prone, time-consuming, and ultimately not worth the performance gains” according to Google. The final goal is usability; F1 has to provide full SQL query support and other functionality users expect from a SQL database: “Features like indexes and ad hoc query are not just nice to have, but absolute requirements for our business.” F1 has added a number of features to those provided by Spanner. It has support for distributed SQL queries, including joining data from external data sources. It also supports secondary indexes that are consistent across transactions; asynchronous schema changes including database re-organizations, optimistic transactions, and automatic change history recording and publishing. The relational features go further than traditional RDBMS systems, particularly in the area of explicit table hierarchy. Tables are organized logically in a hierarchy. Child tables are stored clustered with and interleaved within the rows from its parent table. The primary key of a child table is made up of its own unique identifier along with a foreign key that identifies its parent table. For example, the Ad-Words schema contains a table Customer with primary key (CustomerId), which has a child table Campaign with primary key (CustomerId, CampaignId), which in turn has a child table AdGroup with primary key (CustomerId,CampaignId, AdGroupId). This allows for fast common-case join processing. Protocol Buffers allow the use of repeated fields. These are used instead of child tables when the number of child records would be small. The repeated fields avoids the performance overhead and complexity of storing and joining multiple child records, and are easier for users who can read and write their logical business objects without having to construct multiple table joins. F1 includes a NoSQL key/value based interface that allows for fast and simple programmatic access to rows. Read requests can include any set of tables, requesting specific columns and key ranges for each. This interface is used by the ORM layer and is also available for clients to use directly. Many applications prefer to use this NoSQL interface because it's simpler to construct structured read and write requests in code than it is to generate SQL. This interface can be also be used in MapReduce to specify which data to read. The SQL interface can be used for everything low-latency OLTP queries to large OLAP queries. F1 supports joining data from its Spanner data store with other data sources including Bigtable, CSV files, and the aggregated analytical data warehouse for AdWords. The SQL dialect extends standard SQL with constructs that allow accessing data stored in Protocol Buffers. The Google paper points out that in recent years, conventional wisdom has been that if you need a highly scalable, high-throughput data store, the only viable option is to use a NoSQL key/value store, and to work around the lack of ACID transactional guarantees and the lack of conveniences like secondary indexes and SQL. This wasn’t feasible for AdWords because of the complexity of dealing with a non-ACID data store and necessity for SQL queries. In F1, Google says it has built a distributed relational database system that combines high availability, the throughput and scalability of NoSQL systems, and the functionality, usability and consistency of traditional relational databases, including ACID transactions and SQL queries. The paper concludes: “F1 shows that it is actually possible to have a highly scalable and highly available distributed database that still provides all of the guarantees and conveniences of a traditional relational database.”
More InformationF1: A Distributed SQL Database That Scales Related ArticlesGoogle's F1 - Scalable Alternative to MySQL
To be informed about new articles on I Programmer, install the I Programmer Toolbar, subscribe to the RSS feed, follow us on, Twitter, Facebook, Google+ or Linkedin, or sign up for our weekly newsletter.
Comments
or email your comment to: comments@i-programmer.info

|
|||
| Last Updated ( Tuesday, 22 October 2013 ) |