| Google Supersonic Released As Open Source |
| Written by Kay Ewbank | |||
| Monday, 22 October 2012 | |||
|
Google has open sourced Supersonic, a query engine library that is described as extremely useful for creating a column-oriented database back-end. The announcement on the open source blog says that Supersonic’s main strength is its speed. The engine is cache-aware and makes use of a number of low-level optimization techniques to maximize the speed of query processing, particularly when used on column-based operations. The Supersonic team explains: “By making use of SIMD instructions and efficient pipelining we make columnar data processing very fast.” SIMD ((Single Instruction, Multiple Data) is a technique where multiple processors carry out the same operation on multiple data points at the same time to give data level parallel processing.
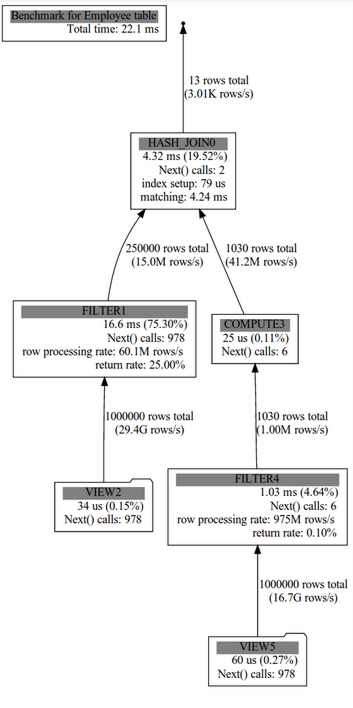
The engine is written in C++ and provides a set of data transformation primitives. These use cache-aware algorithms, SIMD instructions and vectorised execution to exploit the capabilities and resources of modern, hyper pipelined CPUs. The engine is designed to work in a single process, and the team intends it to be used as a back-end for various data warehousing projects. Alongside custom data structures and SIMD, the library has support for standard columnar database operations, and a wide range of specialised expressions (including many math, string and date manipulation functions) The basic Supersonic class is an Operation, and examples of Operations include Compute, Filter, Sort, and HashJoin. You supply a child operation that provides the data, a projector that’s a description which of the output columns should be passed on, and usually some other information such as the expression to be computed, or the order for the sort. More information is included in a short presentation pdf that has some usage examples. Supersonic does not currently provide a built-in data storage format, though the team says “there is a strong intention of developing one”. Currently you persist the data in memory using tables.
More Information
Related ArticlesPerform Data Queries Faster With Drill MemSQL - 80,000 queries per second Google's F1 - Scalable Alternative to MySQL
Comments
or email your comment to: comments@i-programmer.info
To be informed about new articles on I Programmer, install the I Programmer Toolbar, subscribe to the RSS feed, follow us on, Twitter, Facebook, Google+ or Linkedin, or sign up for our weekly newsletter.

|
|||
| Last Updated ( Monday, 22 October 2012 ) |