| PostgreSQL 14 Is Here - A Look At Its Past And Future |
| Written by Nikos Vaggalis | |||
| Friday, 01 October 2021 | |||
|
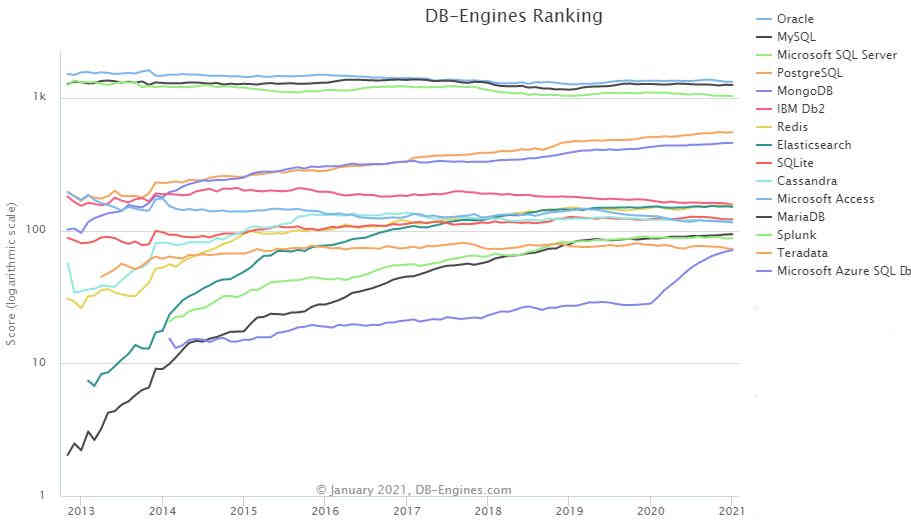
The latest release of PostgreSQL has new and exciting features. We look the most worthwhile of them identified by Umair Shahid, Head of PostgreSQL at Percona while referring to the past ideas that shaped their foundation. Who would have thought back then in the 80's that the humble Ingres fork would, according to the Genealogy of Relational Databases, become one of the most, if not the most, successful DBMS of all time? There are two reasons behind its success; first that it is truly open source at heart, therefore embraced by a strong and vibrant community and then that it was shaped by the visionary ideas Mike Stonebraker had, which formed the basis of the marvel that followed. Let's look into some of them: Supporting ADTs in a Database System Years down the line, PostgreSQL 9.2 introduced yet another type, Range, that represents a range of values of some element type;14 goes one step further by introducing ‘multirange’ types which allow for non-contiguous ranges, helping developers write simpler queries for complex sequences like specifying the ranges of time a meeting room is booked through the day. 'Old' types also get a ramp-up as version 14 continues evolving its JSON support by the addition of the new subscripting syntax. That means that you can access your JSON data as SELECT * Extensible access methods for new data types Another index is that of GIN for Generalized Inverted Index, under which you can index your JSON data in order to enable full-text search. That type of index and others that Postgres supports we took a look at in Deep Dive Into PostgreSQL Indexes. With indexes however comes overhead. The most popular of them, B-tree, when frequently updated tends to accumulate dead tuples that cause index bloat. Typically, these tuples are removed only when a vacuum is run, but between vacuums, as the page gets filled up, an update or insert will cause a page split - something that is not reversible. PostgreSQL 14 can now detect and remove those tuples even between vacuums, reducing the number of page splits and as such index bloat.
Support for Multiprocessors: XPRS Parallelism however extends to distributed workloads too and v14 eases the burden on those workloads by enabling both Query parallelism for table scans as well as bulk inserting on foreign tables (a database object which represents a table present on an external data source which could be another PostgreSQL node or a completely different system). PostgreSQL 14 brings also more refinement to query parallelization by adding support for RETURN QUERY and REFRESH MATERIALIZED VIEW. Staying at the distributed front and that of Replication,Logical Replication which was introduced in PostgreSQL-10 has been tweaked in v14 to allow streaming in-progress transactions to subscribers. Before that the transactions were only getting replicated at commit time and as such there was lag awaiting the transaction to commit in order to transfer the data. The new streaming way, replication performance is getting improved many times over. Performance wise there's yet another tweak in the underlying libpq C based library, which enables the so called "pipeline mode" under which applications can send a query without having to read the result of the previously sent query. That means that a client will wait less for the server, since multiple queries/results can be sent/received in a single network transaction. And while albeit a PostgreSQL 14 introduced feature, the pipeline mode is a client-side technique which doesn't require special server support and works on any server that supports the v3 extended query protocol. Active Databases, Rule Systems and Stored procedures Rules or triggers and stored procedures pioneered under Ingres were yet another construct popularized by Postgres that found its way into all the major database engines. More on that can can be found in Connecting To The Outside World with Perl and Database Events, an article which goes extensively through Rules, Database Events and Stored Procedures under modern Ingres. In v14 stored procedures have been enhanced by being able to return data using OUT parameters, something welcome to devs familiar with other DBMS's such as Oracle. Log-centric Storage and Recovery In PostgreSQL 14, with its new features that help with monitoring and observability, you can now track the progress of all WAL activity, as well as the progress of the COPY commands and replication slots statistics. Those and many more can be found on the version's release notes. The conclusion of this story is that PostgreSQL has been innovating since the 80's and it still is, with every new version, setting the pace for the rest to follow. More InformationPostgreSQL 14 new version docs PostgreSQL 14 – Performance, Security, Usability, and Observability Related ArticlesThe Enduring Influence Of Postgres A Deep Dive Into PostgreSQL Indexes PostgreSQL Is DB-Engines DBMS of the Year For 2020 Connecting To The Outside World with Perl and Database Events Genealogy of Relational Databases Postgres Pro Enterprise 13 Released PostgreSQL Improves Declarative Partitioning PostgreSQL Adds Parallel Query Support
To be informed about new articles on I Programmer, sign up for our weekly newsletter, subscribe to the RSS feed and follow us on Twitter, Facebook or Linkedin. 
Comments
or email your comment to: comments@i-programmer.info |
|||
| Last Updated ( Monday, 04 October 2021 ) |