| NAG Routines for Supercomputers |
| Written by Alex Armstrong | |||
| Monday, 17 June 2013 | |||
|
The new NAG Library for Intel Xeon Phi was recently launched ahead of this year's International Supercomputing Conference, which is being held this week in Leipzig, Germany. NAG is showcasing Mark 24 of the NAG Library for SMP & Multicore at ISC13. The Numerical Algorithms Group (NAG) originally announced a version of its numerical routines tuned to take advantage of the performance of the Xeon Phi last November at the Super Computing conference, SC12. The library is now available in time for ISC '13.
The NAG Library for Intel Xeon Phi contains over 1,700 numerical routines, a number of which have been parallelised and tuned to take advantage of the performance of the Xeon Phi. NAG routines automatically offload, when it is beneficial to do so, compute intensive operations to the Xeon Phi thereby enabling users to transparently exploit the performance of the Xeon Phi. For more advanced users the new NAG Library for Intel Xeon Phi also supports Intel’s Explicit Offload and Native Execution models. To further complement the new Library, NAG provides parallel software engineering and performance optimisation services to advise and give assistance with the migration of application codes in order that they effectively exploit the potential of the Xeon Phi coprocessor. Over a third of the routines in the NAG Library for SMP & Multicore, which has the same mathematical and statistical content as the standard NAG Fortran Library, can now utilize multiple cores. There are newly parallelized routines for global optimization, matrix functions and statistics, including Gaussian mixture model, Brownian bridge and univariate inhomogeneous time series. This latest update to the library (Mark 24) will help numerical programmers exploit the performance potential of multicore systems without having to learn the intricacies of parallel programming.
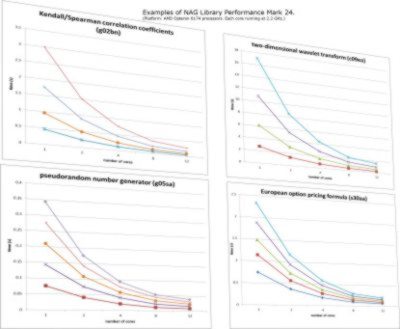
This chart shows examples of NAG Library for SMP & Multicore performance at Mark 24. Each line represents a different problem size. (Platform: AMD Opteron 6174 processors. Each core running at 2.2 GHz.)
More information on NAG support for multicore processors and manycore coprocessors can be found in NAG Library for SMP & Multicore. More InformationNAG Library for SMP & Multicore Related ArticlesNAG for Intel Xeon Phi Coprocessor New number crunching library - NAG C Mark 9 .NET Version of Mathematical Algorithms How to number crunch - NAG for .NET
Comments
or email your comment to: comments@i-programmer.info
To be informed about new articles on I Programmer, install the I Programmer Toolbar, subscribe to the RSS feed, follow us on, Twitter, Facebook, Google+ or Linkedin, or sign up for our weekly newsletter.

|
|||
| Last Updated ( Monday, 17 June 2013 ) |
 According to NAG's announcement:
According to NAG's announcement: