| Microsoft Open Sources Big Data REEF |
| Written by Kay Ewbank | |||
| Friday, 16 August 2013 | |||
|
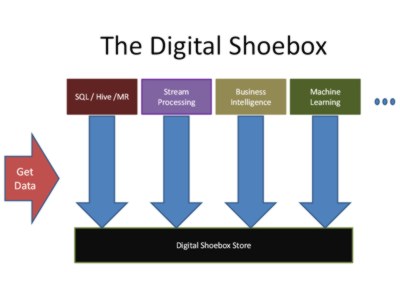
Microsoft is opening up its big data framework REEF as open source. REEF uses Hadoop’s new YARN resource manager, and can be used to build jobs where you need to maintain state even after the job is ended. REEF stands for Retainable Evaluator Execution Framework. Its importance in Microsoft’s ‘Digital Shoebox’ was described by Microsoft Technical Fellow and CTO of Information Services Raghu Ramakrishnan at the ACM Knowledge Discovery and Data Mining conference in Chicago.
Ramakrishnan described the idea of the digital shoebox as online storage in which you should be able to capture any data, react to it instantaneously, and store it for later. You should be able to use any analysis tool to work on the data, anywhere, in any combination, and interactively. Data could come from SQL, Hive, or MR (MapReduce), from stream processing, business intelligence or machine learning. YARN is the resource manager element of the Apache Hadoop project that gives you a way to run and manage multiple jobs of these different types on the same cluster of physical machines. This can reduce the number of machines needed, and also means you can run different analyses of the same data in the one location. According to Ramakrishnan, YARN isn’t ideal for all job types; some, such as machine learning, are problematic because they have specific requirements in areas such as data movement, task monitoring, and the ability to retain result sets for further analysis and modification. REEF, which is a set of libraries that runs on top of YARN will, however, solve some of these problems. REEF has two main parts: Evaluators, which are YARN containers containing REEF services, and Activities, which are the user code that runs inside the Evaluator. Ramakrishnan demonstrated a sample workflow in which YARN would spin up an Evaluator and the Activity code would run inside it and complete. The same Evaluator could then be spun up again maintaining its original state so other Activities could be run against its data. It includes a library of interoperable data management primitives optimized for communication and data movement (which are distinct from HDFS’ notion of storage locality). The library also allows REEF applications to access external services, such as user-facing relational databases. Because Microsoft Research wanted to decouple the lower levels of REEF from the data models and the semantics of systems built on top of it, they developed two new standalone systems. These are Tang, a configuration manager and dependency injector, and Wake, an event-driven programming and data movement framework. Both are language independent, allowing REEF to bridge the JVM and .NET ecosystems. Ramakrishnan said Microsoft Research has built a MapReduce library on top of REEF that runs Hive and Pig, and is an excellent starting point for M/R optimizations such as Caching, Shuffle, Map-Reduce-Reduce, and Sessions. The team has also put together Machine Learning algorithms such as Decision Trees and Linear Models, and plans to add SVD (singular value decomposition ) support ‘soon’. REEF is expected to be open sourced next month. More InformationRelated ArticlesHadoop SQL Query Engine Launched Naiad - Differential Dataflows Most Businesses Moving To Big Data
To be informed about new articles on I Programmer, install the I Programmer Toolbar, subscribe to the RSS feed, follow us on, Twitter, Facebook, Google+ or Linkedin, or sign up for our weekly newsletter.
Comments
or email your comment to: comments@i-programmer.info

|
|||
| Last Updated ( Friday, 16 August 2013 ) |