| OpenAI Benchmarks Economic Impacts of AI |
| Written by Sue Gee |
| Wednesday, 26 February 2025 |
|
Using a new benchmark, OpenAI researchers have revealed a significant shortcoming in the ability of the latest LLMs to perform real-world software engineering tasks. These AI tools may improve productivity, but they are nowhere near ready to take over our jobs.
OpenAI has devised a new benchmark to evaluate and forecast the software engineering (SWE) capabilities of the emerging AI frontier models. It maps model performance to monetary value in order to explore the economic impact of AI model development. With the title SWE-Lancer: Can Frontier LLMs Earn $1 Million from Real-World Freelance Software Engineering? the study takes a novel approach to assessing the practical capabilities of LLMs. The SWE-Lancer benchmark comprises 1,488 freelance software engineering tasks from Upwork, an online platform where freelancers find clients to work on projects remotely. All the tasks have had real payouts to freelancers and this provides: "a natural market-derived difficulty gradient (ranging from $250 to $32,000)". There are two distinct types of task:
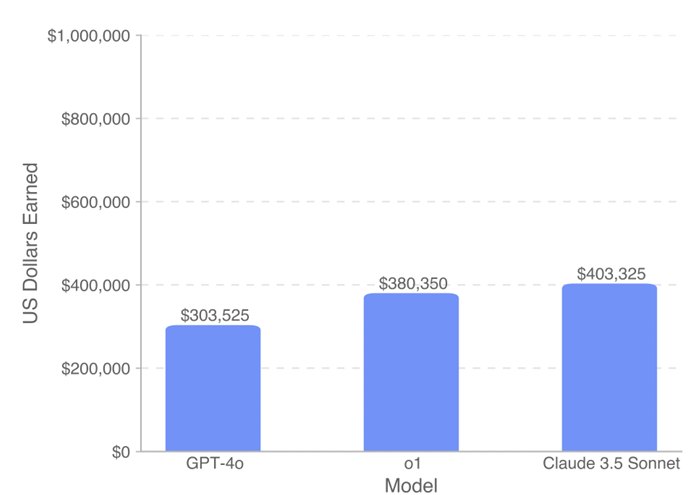
In total the tasks included in the full SWE-Lancer were valued at $1 million. The tasks in SWE-Lancer Diamond, the open-sourced split released for the purposes of public evaluation, contains $500,800 worth of tasks. In terms of difficulty, SWE-Lancer tasks are considered to be challenging: The average task in the Diamond set takes 26 days to resolve on Github and has 47 comments, which include discussion of multiple proposals. On average, IC SWE tasks in the Diamond set require modifying 2 files and 69 lines of code, while SWE Manager tasks require the model to choose between 4-5 proposals. The Open AI models tested with the benchmark were its flagship model, GPT-4o, seen as a very strong general-purpose model, and its more recent o1 model, designed to be strong in complex reasoning tasks by virtue of "thinking" more deeply before responding. The third model was Anthropic's Claude 3.5 Sonnet which is considered to be very strong in logical reasoning and complex task handling. The results reveal that Claude outperformed OpenAI's own models as measured by the SWE Benchmark but still left a lot to be desired in that it would only have earned just over $400,000 of the potential $1,000,000 paid out to human freelancers.
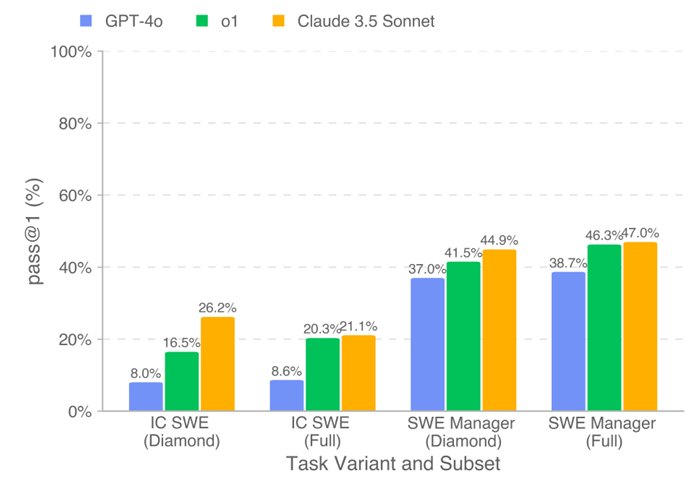
All the models performed better on SWE Manager tasks than on IC SWE tasks as shown below, which is for the first attempt:
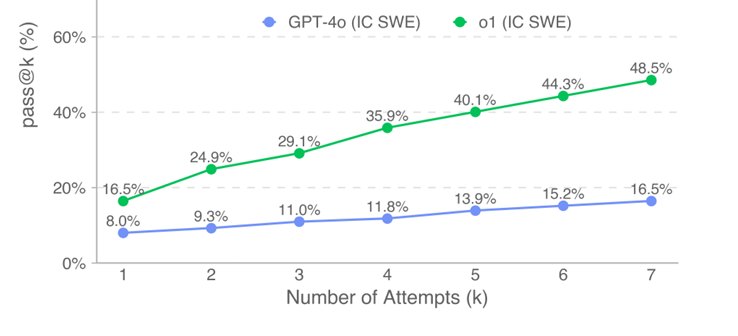
Performance did, however, improve when the two OpenAI models were allowed multiple attempts on IC SWE tasks within the SWE-Lancer Diamond set:
In its concluding Impact Statement the researchers state: “By quantifying AI progress in software engineering, we aim to help inform the world about the potential economic impacts of AI model development while underscoring the need for careful and responsible deployment.” By open sourcing the SWE-Lancer Diamond public eval set OpenAI is proving further support for measuring the economic and social implications of AI models.
More InformationIntroducing the SWE-Lancer benchmark SWE-Lancer: Can Frontier LLMs Earn $1 Million from Real-World Freelance Software Engineering? by Samuel Miserendino, Michele Wang, Tejal Patwardhan, and Johannes Heidecke
Related ArticlesOpenAI o1 Thinks Before It Answers JetBrains Adds Claude Support To AI Assistant Claude Engineer Amplifies Your Code To be informed about new articles on I Programmer, sign up for our weekly newsletter, subscribe to the RSS feed and follow us on Twitter, Facebook or Linkedin. 
Comments
or email your comment to: comments@i-programmer.info |
| Last Updated ( Wednesday, 26 February 2025 ) |