| Learn To Chat with Your Data For Free |
| Written by Nikos Vaggalis | |||
| Monday, 28 August 2023 | |||
|
"LangChain: Chat with Your Data" is a brand new free and short course by Harrison Chase, CEO of LangChain himself, to learn how to use LLMs to converse with your own data. With around an hour of content, it is hosted on Andrew Ng's Deeplearning AI platform.
What's the next logical step after playing with ChatGPT or any LLM (Large Language Model) for that matter? Instruct it to use your own data! LLM models are pre-trained on huge amounts of text available on the internet, so wanting to get it to answer questions, on i. e. your documents or emails, would maximize the potential. Note that this is not the same as fine-tuning a LLM on your own domain specific data, like medical diagnosis or financial data where the original model draws from its pre-trained experience
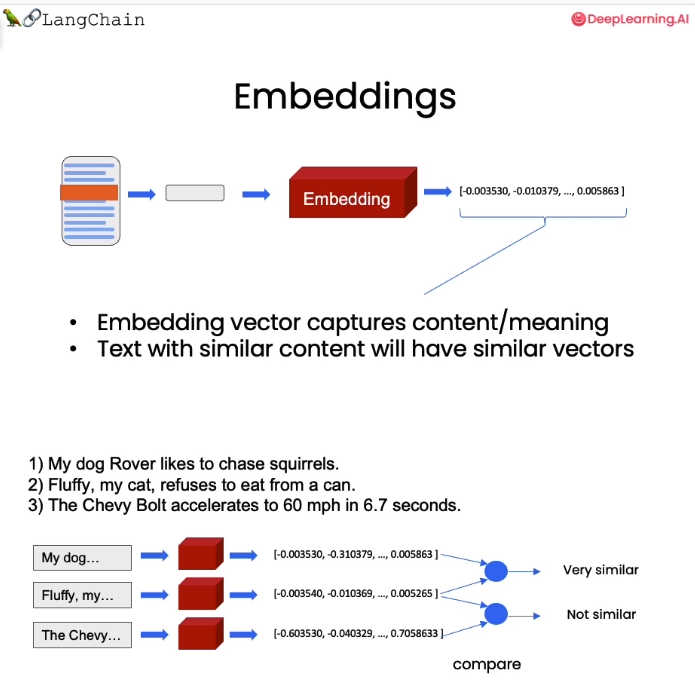
For casual everyday use it's just fine, however, and can work with a good percentage of success on your personal data, your company's proprietary documents, as well as data or articles that were written after the LLM was trained. As a matter of fact, for those more specialized cases a dedicated course on fine tuning LLM's has been just released on the same platform. With that out of the way let's now focus on the course itself. Of course, we will use LangChain in order to chat with our data. LangChain is a library that abstracts the details of specific LLM providers so that with just one library we are able to chat with a variety of LLMs like OpeanAI's or Hugginface's for instance. So, Chapter 1 is about document loading because in order to create an application where you can chat with your data, you first have to load your data into a format where it can be worked with. The chapter shows how to do that using LangChain's document loaders which can work with many different formats;plain text, markdown, pdf etc. Throughout the course, the video tutorials run side by side with a Jupyter notebook that contains the relevant Python code that you can work with live. The next step after loading the data and before entering them into the Vector store, is to split them into smaller manageable chucks. We use LangChain's Text splitters for that. Chapter 3 is about vector stores and embeddings. Embeddings take a piece of text, and create a numerical representation of that text. Text with similar content will have similar vectors in this numeric space. What that means is we can then compare those vectors and find pieces of text that are similar. We use NymPy to convert the text into embeddings and then load them into the Chroma vector store. With that procedure, and without even touching the LLM yet, we still can do useful similarity searches.
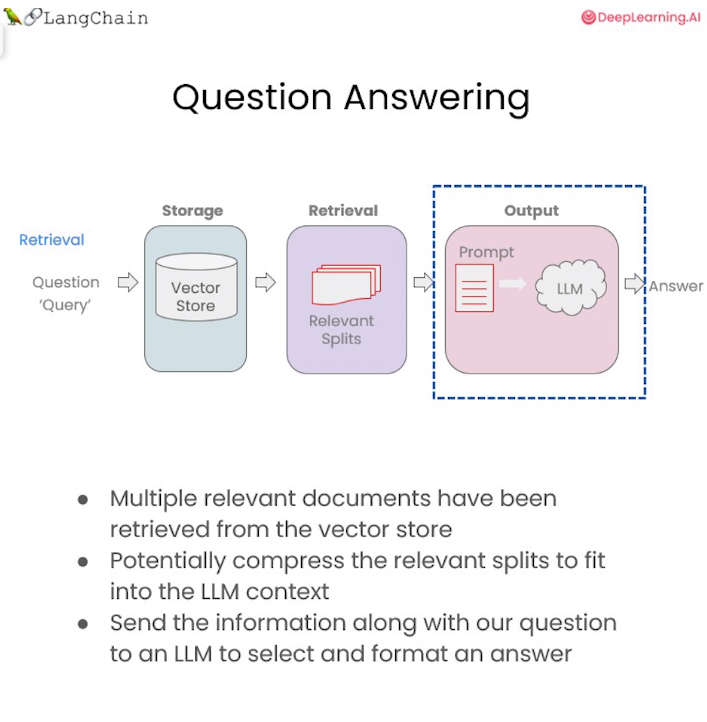
In fine-tuning the search to return more relevant results, we delve into the Retrieval chapter which does that using Maximum Marginal Relevance, or MMR for short. Chapter 5, Question Answering, is finally where the LLM gets involved. We take the documents, take the original question, pass them both to a language model, and ask it to answer the question. Building on the previous work we've done so far, we loaded the documents, split them, vectorize them to finally pass those splits along with a system prompt and the human question to the language model in order to the answer. Now we can ask questions and get answers, but there's no state in between;our model does not remember. In the last chapter we give it some memory for that purpose, ending up with a fully-functioning chatbot! This concludes the course, all in under 1 hour. Quick, to the point and covering a very useful case of LLMs. Recommended.
More InformationLangChain: Chat with Your Data Related ArticlesTake Stanford's Natural Language Processing with Deep Learning For Free
To be informed about new articles on I Programmer, sign up for our weekly newsletter, subscribe to the RSS feed and follow us on Twitter, Facebook or Linkedin. 
Comments
or email your comment to: comments@i-programmer.info |
|||
| Last Updated ( Monday, 28 August 2023 ) |