| Using AI For Duplicate Question Detection On Stack Overflow |
| Written by Sue Gee | |||
| Friday, 14 October 2022 | |||
|
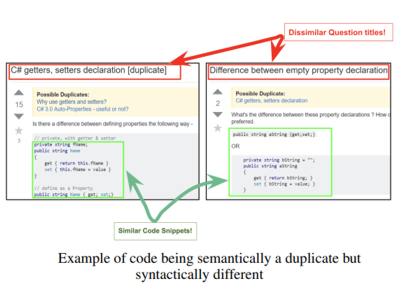
Here is yet another use case for neural networks - this time to identify duplicate questions on Stack Overflow so as to eliminate them, thereby improving the quality of the resource. Finding helpful information on Stack Overflow is difficult because there is so much of it. As of March 2021 it comprised 21 million questions and 31 million answers. Three years ago, in an report introducing a fledgling tool that was attempting to help find relevant answers which although promising doesn't seem to have progressed since, I reached the conclusion: What is really needed is some one to curate the database that is Stack Overflow, weed it, prune it, merge answers into something complete. Perhaps this is too much to ask of AI at the moment. The researchers at Carnegie Mellon who propose two new AI-based approaches to identifying duplicate questions start from the premise that: There has a been a significant rise in the use of Community Question Answering sites (CQAs) over the last decade owing primarily to their ability to leverage the wisdom of the crowd. Duplicate questions have a crippling effect on the quality of these sites. Tackling duplicate questions is therefore an important step towards improving quality of CQAs. In the paper Mining Duplicate Questions of Stack Overflow which can be accessed via arvix the researchers explain that duplicate questions on CQAs such as Stack Overflow increase the number of irrelevant search results forcing users to search longer. They also deter users from answering questions. Whereas previous research in duplicate question detection has focused on the text content of questions, they argue that little attention has been paid to the accompanying code which they want to leverage: We believe that, in addition to using text content, we can leverage the large number of code snippets available on sites like stackoverflow to detect duplicates. The paper presents this example of two questions marked as duplicates by Stack Overflow moderators.
The paper states that the overlap in the question title and text would easily elude an ordinary text based classifier but that inspection of the code reveals that the questions are in fact quite similar, commenting: Intuitively, this follows from the fact that coding standards and idiomatic code renders code snippets more similar than natural language text, despite differences in individual coding style. The paper goes on to present a Long Short-Term Memory (LSTM) model incorporating code and using annotations to distinguish between code and text. It then outlines two different approaches the researchers want to experiment with during the course of the project. The first is a Siamese neural network (sometimes called a twin neural network) which uses the same weights while working in tandem on two different input vectors to compute comparable output vectors. The second is a CNN-based approach which learns over a feature-grid based representation of the question representations. As the conclusion of the paper reiterates: The important feature of the project is using code embeddings to enable the detection of semantic and logical similarity across seemingly different code snippets. Maybe this is the key to giving AI a chance to transform the Stack Overflow Q&A database into a really useful resource.
More InformationMining Duplicate Questions of Stack Overflow by Mihir Kale, Anirudha Rayasam, Radhika Parik and Pranav Dheram Related ArticlesCROKAGE AI Gets Stack Overflow Answers For You Newbies, Lurkers and Experts on Stack Overflow How To Ask A Successful Question on Stack Overflow Stack Overflow Considered Harmful? How To Ask A Successful Question on Stack Overflow To be informed about new articles on I Programmer, sign up for our weekly newsletter, subscribe to the RSS feed and follow us on Twitter, Facebook or Linkedin. 
Comments
or email your comment to: comments@i-programmer.info |
|||
| Last Updated ( Saturday, 15 October 2022 ) |