| You Only Look Once - Fast Object Detection |
| Written by Mike James | |||
| Wednesday, 23 August 2017 | |||
|
Neural networks have made computer vision possible, but there are still many difficult situations that they don't work so well in. If you want to do object detection and labeling then the traditional approach is likely to be too slow, but now we have YOLO V2 which can label entire images in one operation. YOLO, and yes they make a lot of play of the confusion with Bond film You Only Live Once as you will discover if you watch almost any of the researchers' presentations, is a sort of breakthrough. I say "sort of" because it is another demonstration of the almost universal fact that all you really need is a big neural network and a lot of data. This is not to belittle the achievement as there are lots of details to get right to make something like YOLO work well, but this shouldn't cover up the fact that it is applying some very simple general ideas. There are two general approaches to object detection - computational vision and neural networks. In the case of computational vision you make use of complex features which are highly characteristic of the object you want to detect and track. These systems are particularly good at tracking and not so good at detection in general. Neural networks are much better at detection and not bad at tracking. The problem is that the standard way of doing the job is very slow. To put it simply, what you do is train a network to recognize a picture of a cat. You show it lots and lots of pictures of cats and then, once trained, you have a cat detector. You then scan it across an image and compute its output at all the possible locations you might find a cat. You also repeat the task at different scales to make sure you detect cats at different distances. At the end of the day you draw bounding boxes around the regions of the image where your cat detector outputs a high probability that there was a cat. What YOLO does it to go back to the basic idea of using a neural network to learn the connection between the input and the output that you are really interested in. You aren't interested in detecting a cat photo, you are interested in putting a bounding box around any area in a photo that might contain a cat. This approach is often referred to as "end-to-end neural network learning" and it is is what made DeepMind's approach to playing computer games and Go different.
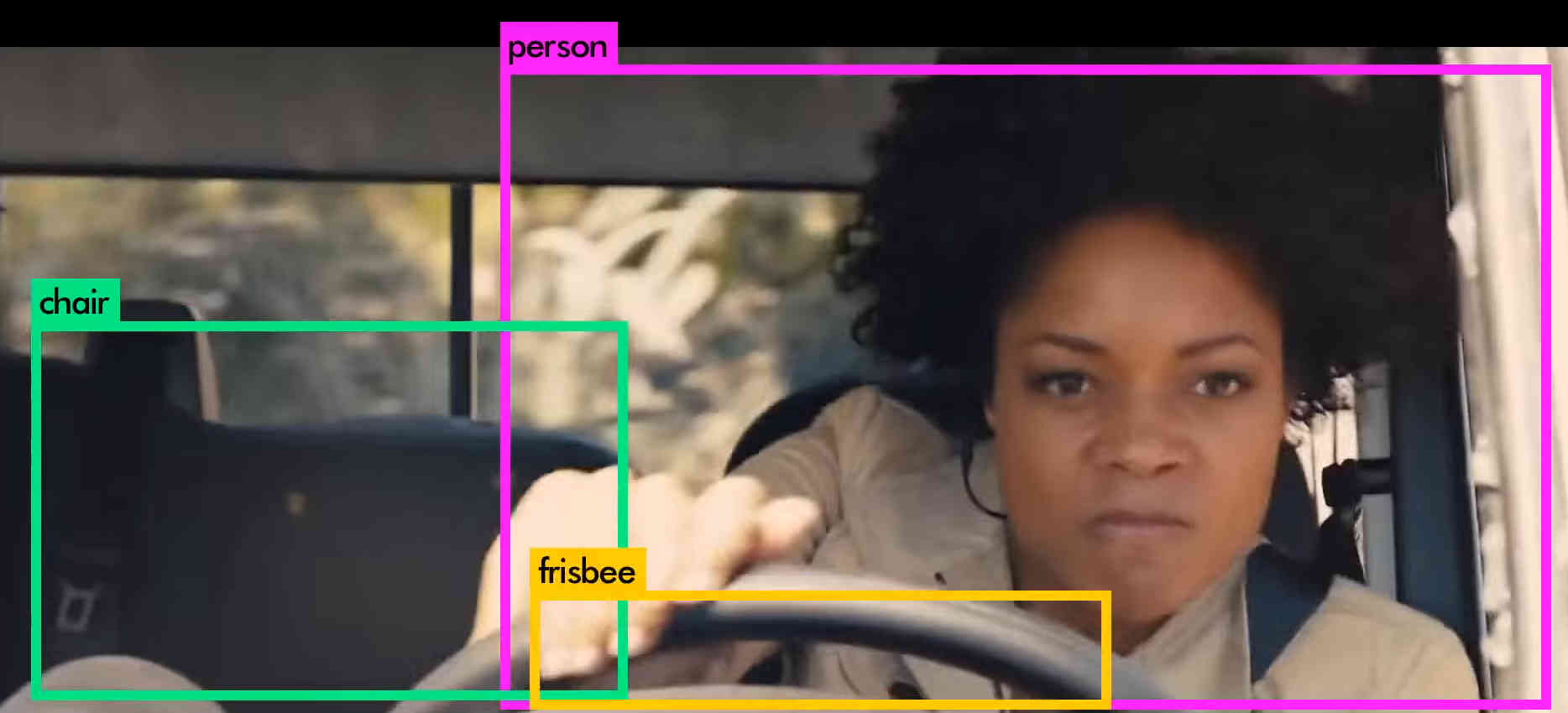
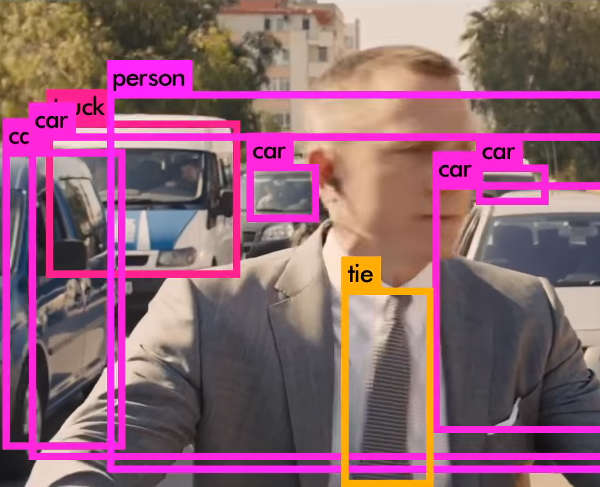
In the case of YOLO the neural network is trained to put bounding boxes, complete with probabilities, around areas that might contain an object of various sorts. This is why it is called You Only Look Once. The alternative approach looks for a cat at every possible location and hence "looks" repeatedly. YOLO really does only look at the entire image just once. This is the reason it is so unbelievably fast. In one forward network computation, still a lot of multiplies, nonlinear functions and additions, it computes all the bounding boxes you see in the demos. Now take a look at the demo - and yes it is the other YOLO that is used as the input material:
It all happens so fast that my advice it to pause the video at regular intervals to get an idea of what bounding boxes and labels are actually applied to. Notice that the errors are understandable in that the labels incorrectly applied by the network are mistakes that seem reasonable to a human.
There are still some problems with YOLO - it isn't the most accurate object detector available - but when you take into account its speed this might not be a problem. If you need an object detector for something that needs real-time decision-making it is currently the only approach that gets close to being fast enough. There are also probably ways of using its speed to improve the performance by taking into account spatial correlations - i.e. a pink elephant that appears in a single frame is unlikely to be real. A pink elephant that persists and moves along a plausible trajectory is more likely to be a person dressed in a costume, no matter how unlikely. Another really impressive demo is the recent TED talk where YOLO's realtime abilities were put to the test:
An important point is that various trained versions of YOLO are available to download and the project is open source. There are also a range of demo downloads including one that will work with a video camera feed. What is important about YOLO, as well as its performance, is that it offers the potential to be used as a subsystem in something more advanced. If I were a robot researcher I would certainly be thinking hard about what I could do with YOLO as part of my onboard software system. As to self driving cars, well the usefulness of YOLO is obvious and it is fast enough. Given more data YOLO can improve its accuracy without getting any slower. Perhaps this is the future for AI. No more breakthroughs, just end-to-end learning from here to there. More InformationYOLO9000: Better, Faster, Stronger (paper) YOLO: Real-Time Object Detection Related ArticlesAlien FaceHugger v Predator - Face Tracking Hots Up Google Releases Object Detector Nets For Mobile We May Have Lost At Go, But We Still Stack Stones Better The Shape Of Classification Space Is Mostly Flat Microsoft Cognitive Toolkit Version 2.0 Evolution Is Better Than Backprop? To be informed about new articles on I Programmer, sign up for our weekly newsletter, subscribe to the RSS feed and follow us on Twitter, Facebook or Linkedin. 
Comments
or email your comment to: comments@i-programmer.info
|
|||
| Last Updated ( Wednesday, 23 August 2017 ) |