| Advanced Perl Regular Expressions - The Pattern Code Expression |
| Written by Nikos Vaggalis | |||
| Monday, 08 February 2016 | |||
|
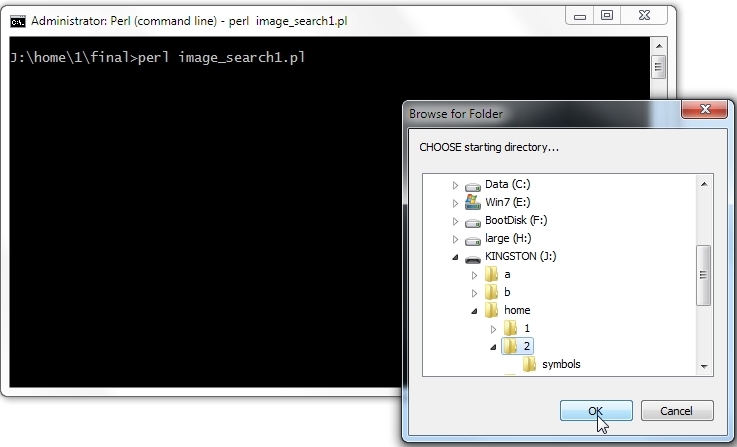
In this part of our series exploring Perl RegEx we are going to look into another advanced construct, that of the pattern code expression ??{code}. According to the official perldoc this "..is like a regular code expression, except that the result of the code evaluation is treated as a regular expression and matched immediately." We will also attempt to combine it with the ?{code} code evaluation expression, covered in the first part of the series. We'll build on the same scenario, in which we were receiving a serialized stream from a web service that had all special characters encoded in HTML entity hex encoding. The requirement was to convert them back to their actual character representation, for example '£' would become the pound £ symbol). Additionally we are going to search for files that contain the decoded string in their names. So for a sequence comprised of "image_of_a_£" we are going to recursively search inside a designated directory for any instances of 'image_of_a_£' in the filenames. In order to choose the starting directory we are going to create a dialog box by making use of raw Win32 API calls, thus instead of typing the path and the directory's name in the console we are going click on it by navigating through the file system structure as presented by Windows. Explaining how this works is outside the scope of this tutorial. Suffice it to say that by clicking on a directory, its full path will get assigned to variable $dir.
sub choose_dir {
my $SHBrowseForFolder=
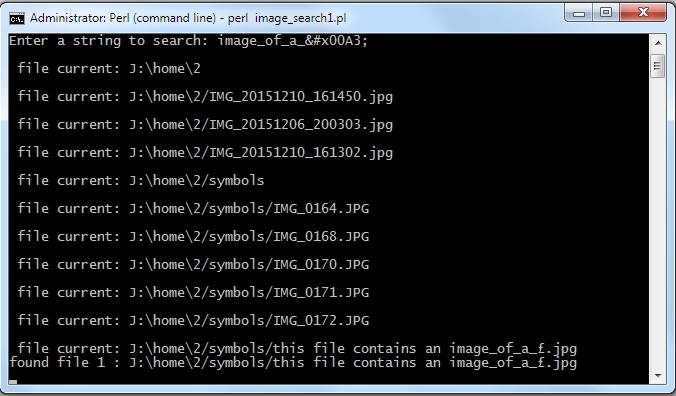
We then ask the user for the string (that includes the HTML entities) to search for against the filenames: print ("Enter a string to search: ") &&
Then we use module's File::Find 'find' subroutine for diving into the directory, and recursively process all subdirectories and files found within: find(\&wanted,($dir)); The 'wanted' subroutine is a user-defined callback that find will call upon visiting each file. It is a very simple subroutine that just checks every filename,except the directory names (!-d $File::Find::name), against the search string for a match: sub wanted {
The variable $count is decorated with the state operator which gives it local subroutine scope and enables it to maintain ...state throughout the recursive calls of the subroutine, thus keeping track of the number of files examined. All of this acts as wrappers around the core of the program, the regex itself: /(??{
$search=~s@(&\#x....;)
(?{
if (defined($1)) {
decode_entities($1)
}
})@$^R@xg;
quotemeta $search
})/xi
Let's dissect it. The occurrences of @ are there because we cannot use / as a delimiter for the inner pattern as / are already in use by the outer pattern /(??{,so we are forced into choosing another delimiter if we want the regex to compile,which in this case is the character @ The outer })/xi allows the pattern to be flexible against whitespace since it won't consider it as part of the actual pattern thus enabling us to break the pattern apart and style it, indent it or even comment on it. Then the /i turns on the case insensitive mode. $search=~s@(&\#x....;)
(?{
if (defined($1)) {
decode_entities($1)
}
Whenever (&\#x....;) matches a hexadecimally represented HTML entity, the ?{code} construct assigns the match into variable $1 (represented by the if (defined $1) block) which subsequently calls decode_entities on it to translate it to the actual character representation.Therefore £ becomes £. Where there is no match we leave any other characters, such as 'image_of_a_', untouched. That character ends up into variable ^$R which works with the substitution operator to replace the £ in the original $search string into £. Thus the new value of the $search string becomes 'image_of_a_£' . After we post-process the new value with the quotemeta operator, we feed it to the next component in the pipeline, the outer ??{}. ??{} treats it as an in place pattern, in effect /image_of_a_£/, which is then used with $File::Find::name=~ attempting to match against a filename. For example, given the filename 'this_file_contains_an_image_of_a_£', the outcome would be 'this_file_contains_an_image_of_a_£'=~/image_of_a_£/.
But what is quotemeta's purpose? We use it so that we instruct the regex engine to not interpret characters as a special metacharacters. In other words, if the string contains an asterisk (ASCII 2A), as in 'image_of_a_A*', once translated it would become 'image_of_a_*' , with the resulting pattern being /image_of_a_*/ The asterisk would then be used as a metacharacter special to the regex engine that would alter the meaning of the pattern to 'find 0 or more instances of image_of_a_' instead of 'match an instance image_of_a_* .This would potentially match everything, even against unrelated strings, since for the condition to be satisfied there are zero occurrences of 'image_of_a_' required. This would, for example, even match against 'picture_of_the_moon', producing is a false positive. Quotemeta in effect disables this feature by effectively wrapping the string into \Q...\E , hence treaing * as the literal character, pertaining to no special meaning All this could very well be achieved by other means, but when the language offers you the opportunity and capability to simplify matters by creating more compact and robust code, why not gracefully accept it? The code was developed and tested on a Windows 7 32-bit machine, ActiveState Perl 5.20, and can be found online on pastebin, http://pastebin.com/idjXRWYa. Related ArticlesAdvanced Perl Regular Expressions - Extended Constructs
To be informed about new articles on I Programmer, sign up for our weekly newsletter,subscribe to the RSS feed and follow us on, Twitter, Facebook, Google+ or Linkedin.

Comments
or email your comment to: comments@i-programmer.info |
|||
| Last Updated ( Monday, 25 July 2016 ) |