| RAID - Storage Made Smart |
| Written by Harry Fairhead | |||
| Friday, 22 November 2024 | |||
Page 1 of 2 Storing data is fundamental to programming. We often think of the task as something that just involves hardware, but we can take basic storage devices and use them in conjunction with clever algorithms to make the whole thing work better. Storage can be about software. The idea of RAIDRAID, “Redundant Arrays of Inexpensive Disks”, is an idea whose time has more than come. When it was invented back in 1987 the “Inexpensive” part of the name was something of a joke. For a desktop machine, the cost of a single hard disk was just affordable, the idea of using a whole set of them was out of the question. Today, of course, you can get a high-capacity, high-performance drive for less than $50 and putting multiple units together to make something much better than a single drive is a very attractive proposition. So what is RAID? How does it work and how can you get to make use of it? The RAID idea is very simple - take multiple drive units and connect them together to make them work as a single “virtual” storage device. You treat a RAID system as if it was a single disk drive or storage volume, even though it might consist of multiple physical drives. This sounds obvious enough but what does it get you in addition to more cost, more heat and more noise? RAID enthusiasts often forget that the purpose of the whole idea isn’t obvious and hence don’t bother to explain. There are three main reasons for wanting to implement RAID.
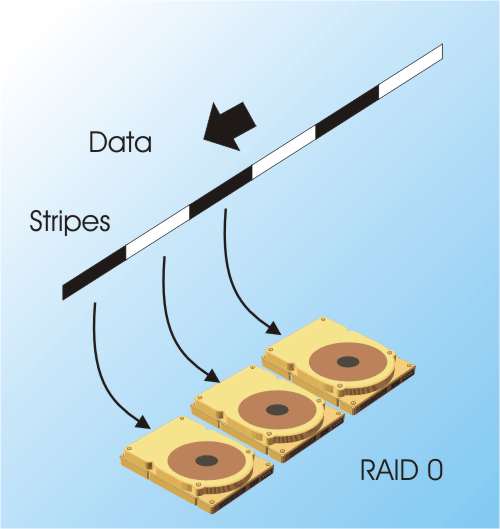
It's important to remember that whatever RAID scheme you choose, it is not a substitute for backup. A RAID system may be more reliable but it can still fail. An earthquake could take out the building and your data. Much smaller disasters, such as a cascading power supply failure, can easily destroy all of the disks in an array - so backup is not optional, even with a RAID system. Knowing how to keep data safe is an essential skill for big companies that rely on their computers, taking an information assurance training will help you acquire these skills from the comfort of your home Six basic types of RAIDThe reasons for building RAID systems seem desirable enough so how do we achieve them? There are a number of types of RAID differing in how much they satisfy each of the objectives. RAID 0 - StripingRAID 0 uses a technique called “striping” which is employed in other RAID versions. The basic idea is that if you want to write a file to the disks it is split up into fixed size blocks. The first block is written to the first drive in the array, the second to the second and so on until we get back to the first drive again. You can see that RAID 0 makes the array of drives look like a single virtual drive by spreading the data over all of them. As long as the drives can function independently of one another there can be a performance gain but this also depends on choosing the correct block or ‘stripe’ size to optimise the performance. In practice RAID 0 should be avoided at all costs for the simple reason that the failure of any drive in the array results in the complete loss of data and data recovery is made much more difficult by the way that the data is spread across the drives.
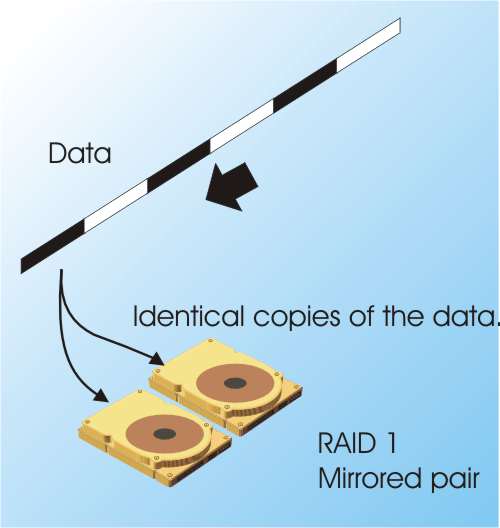
RAID 1 - MirroringThis is often referred to as mirroring. Additional drives simply backup the original, i.e. they mirror the first drive. In most cases mirroring is used with two drives as this provides the maximum benefit for smallest cost. It doesn’t increase the storage capacity, i.e. two drives provide the same capacity as one, but it does improve data reliability. If one of the drives fails there is still a copy of all of the data on the working drive. You can replace the failed drive with a fresh drive and the mirror copy will be regenerated. Mirroring can also increase performance if it is arranged so the data is read from alternate drives, but this isn’t really the main reason for using Mirroring. |
|||
| Last Updated ( Monday, 25 November 2024 ) |