| A Generic SQL Server Compression Utility |
| Written by Ian Stirk |
| Tuesday, 26 February 2013 |
|
We are familiar with the idea of compressing images to reduce the storage space required and make them faster to display. Here compression is applied to database tables and indexes to improve query performance.
This article describes a generic utility that compresses all the relevant tables and indexes in a database. Typically the resulting database is reduced to about 30% of its original size, and overall query performance is improved. BackgroundGenerally, most databases have significantly more reads than updates, and often the required data is on the same physical database page. Compression allows more data to be stored on each page, and subsequently more data to be retrieved per read, resulting in both reduced storage and improved performance. There are many advantages in compressing the tables and indexes of a database, including:
There are however some disadvantages too, including:
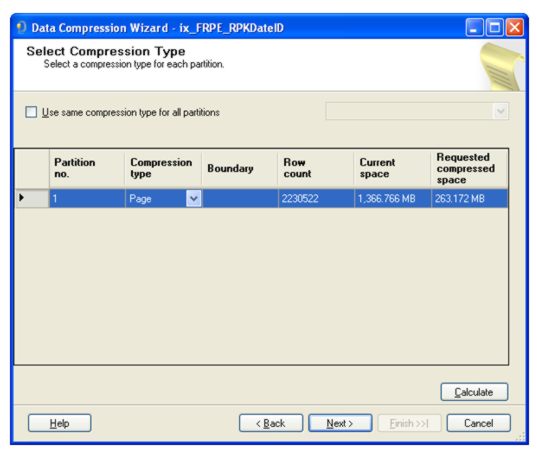
Warning: As with any system change, it is recommended to test this utility on a test system first, and then decide if compression is advantageous for your database. Compression via GUISQL Server provides a facility that estimates the compression saving, for a given table or index, and then allows you to compress the given table or index individually. This facility can be accessed from within SQL Server Management Studio, by right clicking on a table or index, selecting Storage, then Manage Compression. This brings up the Data Compression Wizard. Selecting the type of compression from the dropdown and then pressing the Calculate button results in a compression estimate, as shown in the figure below:
(click to enlarge) The ProblemWhile the Data Compression Wizard GUI is useful, it does not compress all of the tables and indexes in the database in one step. The generic compression utility described in this article overcomes this deficit. The UtilityThe generic script provided in this article, runs the inbuilt compression estimation stored procedure (sp_estimate_data_compression_savings) for each table and index in the database. The output from this stored procedure can then be used to determine if compression of a given table or index should occur, for example, it is possible to compress only those tables where the compression saving is at least 20%. The current code compresses any tables/indexes where the compression saving percentage is greater than 0%. The T-SQL code used to create this utility is available from the CodeBin. How it worksThe script starts with the statement SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED. The purpose of this is to ensure the SQL that follows does not take out any locks and does not honour any locks, allowing it to run faster and without hindrance. A work table, named #BaseSQL, is created to hold the SQL that is used to estimate the degree of compression. Another work table, named #CompressionResults, holds the actual results of running the compression estimate. The utility first builds the SQL relevant to estimate the compression saving, for tables (i.e. clustered indexes and heaps). Later it does a similar thing for non-clustered indexes. It does this separately because the syntax for building the SQL for tables and indexes with compression is different. The SQL to do this for tables is: (click to enlarge)
Note: System indexes are ignored, and only objects with at least 1 row are considered (this eliminates statistics objects). The SQL stored in the table #BaseSQL, is combined together and stored in a variable named @CompressionEstimationSQL. This variable is the input to the sp_executesql stored procedure, to actually run the SQL. Running this SQL results in the compression estimation stored procedure being run for all the relevant tables. The results are stored in the table named #CompressionResults. This is shown in the SQL snippet below: -- Build SQL to run to estimate compression saving.
-- Run to estimate the compression saving. The same process is then applied to the non-clustered indexes, and the results again stored in the table named #CompressionResults. Note, an indicator is stored in the column named AlterTableOrIndex, in the table to indicate if the underlying object is a table or index (remember the syntax to compress is different for each), also the actual SQL used to compress the table/index is also given in a column named AlterTableOrIndexSQL. Additionally, the compression change is calculated as a percentage, and stored in a column named estimated_page_savings_percent. This is later used to determine if the table or index should be compressed. This is shown in the SQL snippet below:
In the example code given, all tables/indexes with some compression saving (i.e. estimated_page_savings_percent > 0) are compressed. The SQL to run to compress the tables/indexes is combined and stored in a variable named @CompressTablesAndIndexesSQL, as shown below:
You may want to amend this SQL to only compress tables where the compression saving is 20% or more, also there may be some tables/indexes you want to exclude from compression, this can be done here too. The SQL in the variable @CompressTablesAndIndexesSQL is used in the debug section of code to prints out the compression SQL that will run, this can be useful in examining what tables/indexes will be compressed, you can see this in the below SQL snippet:
Note: it is recommended to comment out the following line if you want to run the routine in debug mode: To run the SQL that actually compresses the tables/indexes, the variable named @CompressTablesAndIndexesSQL is passed as a parameter to the sp_executesql stored procedure. This is shown below:
Since the utility can be quite intensive in writing changes to the database log, it may be advantageous to change the database recovery model to SIMPLE MODE for the duration of the script (it is recommended to backup the database first). ConclusionThe generic compression utility described in this article will compresses all the relevant tables and indexes in a database. Typically the resulting database is reduced to about 30% of its original size, and overall query performance is improved. If you would like the code for this article register with I Programmer and visit the CodeBin.
Ian Stirk is the author of SQL Server DMVS in Action (see side panel, and our review) and the following articles:
Improve SQL Performance – Know Your Statistics Improve SQL performance – An Intelligent Update Statistics Utility Identifying your slowest SQL queries Improve SQL performance – find your missing indexes A Generic SQL Performance Test Harness
Comments
or email your comment to: comments@i-programmer.info
To be informed about new articles on I Programmer, subscribe to the RSS feed, follow us on Google+, Twitter, Linkedin or Facebook or sign up for our weekly newsletter.
|
| Last Updated ( Friday, 01 March 2013 ) |