| Hit Highlighting with dtSearch |
| Written by Ian Elliot | |||
| Wednesday, 05 October 2011 | |||
Page 1 of 2 What do you do with your search results after you have obtained them? We explore hit highlighting with dtSearch and C#. In the first part of my exploration of the search and indexing system dtSearch, I covered the basic principles of operation. Now we consider what to do next once you have some search results. What do you do with your search results after you have obtained them? It is a good question. In many cases it is enough to simply list the files that contain the hits. But what if your users want to look inside the files and see where the hits have occurred? This is a nightmare of a job if you have to start from scratch. All those file formats and then there is the bother of finding out how to highlight the hits in each format. No - it probably isn't worth the effort. Converting file formatsThe good news is that if you are using dtSearch, which you can try for yourself by downloading the 30-day evaluation from dtsearch.com, you can use a range of file and container parsers. dtSearch has its own file parsers supporting popular file types like MS Word, Excel, Access, PowerPoint, CSV, HTML, PDF, XML/XSL, emails and attachments, ZIP files, etc. The file parsers are used by the indexing engine to look inside each document and it is also used by the FileConverter object to allow you to process documents into a standard format so that the results of searches can be presented to users. Getting startedIt is assumed that you already know how to create an index and search it using say C#. If not read Getting started with dtSearch, but to give us something to work with we will perform a simple search for the single word "Jeep" in an index that has already been constructed. First we need a SearchJob object: SearchJob SJob1 = new SearchJob(); which we make ready to perform the search on the index: SJob1.BooleanConditions = "Jeep"; You can, of course, customize to search for any target in your own index. Finally we execute the search: SJob1.Execute(); This populates a Result object with all of the information needed about each file found. To make things easier to follow, we can create a direct reference to the results of the search: SearchResults Results = SJob1.Results; SearchResultsThe search results contains a list of documents and associated properties that was returned from a search. We have encountered it before, but is is worth a few moments considering it in more detail. You might expect SearchResults to be a simple collection object, but if you consider the problems involved in creating a collection object consisting of a range of documents you can see that it is better to only retrieve a document when it is needed. To retrieve a document and its associated properties you simply use the GetNthDoc method, which loads the Nth document in the results list into the SearchResults objects CurrentItem property. For example, to get the first document you would use something like: Results.GetNthDoc(0); Once you have the Item you can make use of its properties to work with the properties of the document and the search. For example, you can check the document's type using its TypeId property. This is an integer but its ToString method has been overridden to provide a string identifier. So, for example: MessageBox.Show(Item.TypeId.ToString()); displays
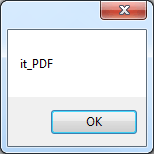
which indicates that the first document in the list is a PDF. You can discover the full range of document types by examining the TypeId enumeration. As well as details of the document, the SearchItem object also contains details of the hits, i.e. the details of where the target phrase was found in the document. You can use these details to manipulate the document to show, say, where the hits occurred. A central issue is locating where a hit occurred and this can be achieved using the Hits array which contains the offsets of the words that have been matched to the search target. If you examine the range of similar properties then you should be able to see how to highlight the hits - but you probably aren't looking forward to such detailed, and let's face it boring, coding. The good news is that it has all been done for you and in a way that does so much more than you would achieve with a basic approach. |
|||
| Last Updated ( Friday, 21 September 2018 ) |