|
Page 1 of 2 In this interview, which completes a trilogy on implementations of Perl 6, we talk to Flávio Glock about Perlito, the compiler collection that implements a subset of Perl 5 and Perl 6. It is a very interesting discussion that revolves around topics like parsing, bootstraping, VM's, optimizations and much more.
Flávio Glock Soibelmann has developed several CPAN modules for the DateTime Dashboard. He is currently one of the developers of Perl and Perlito is his main current project.

Perlito is an intriguing piece of technology capable of compiling Perl 5 or Perl 6 programs into various backends, currently including JavaScript, Python, Ruby and Go. It may be extended to other backends as the project is very active.
Perlito's potential is very exciting as it is open to hacking extensions and backends, while also acts as a platform for experimenting with language semantics, optimizations and code generation. Aside from that research and develop aspect, it also bears a practical face for end-users, as Perl in the browser demonstrates.
Looking into the future and in the case that Perlito manages to implement the full language set, then it maybe would spearhead the reshaping of Perl's landscape.
NV: So Flávio, you work for Booking.com in the code optimization sector?
FG: Yes, for about 5 years now.
NV: What is this area of activity occupied with - code refactoring, experimenting with algorithms, tweaking Perl’s internals?
FG: It is mostly about identifying bottlenecks - and then fixing; we have some people tweaking Perl’s internals too, but this is not my area.
NV: Bottlenecks resulting from non-optimized code or you also identify networking related ones?
FG: I don't look at networking in terms of network problems, but from the software point of view. Reducing the transmitted data size is important for mobile, so reducing resource usage in general is something I work on.
NV: What kind of other bottlenecks can there be?
FG: CPU is an important bottleneck - you want to have results as fast as possible, and pre-calculation plays an important role in reducing latency. Memory, database and network are the other bottlenecks. We balance the processing between Perl, MySQL, and eventually memcached and other technologies.
NV: So what is the motivation behind Perlito?
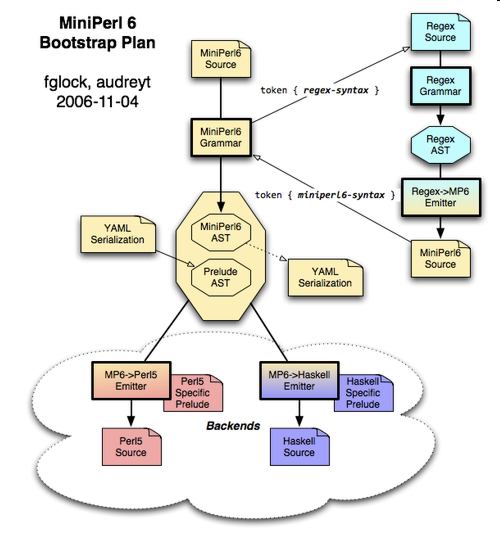
FG: Perlito started as a bootstrapping compiler for Pugs - we wanted to rewrite Pugs in Perl6. It was called "mini-perl6" at that time. The plan was to support both Haskell and Perl5 as backends
I think the regex compiler for Pugs still uses mini-perl6:
http://search.cpan.org/dist/Pugs-Compiler-Rule/
This is the mini-perl6 source code for the module:
http://cpansearch.perl.org/src/FGLOCK/Pugs-Compiler-Rule-0.37/examples/Grammar.grammar
NV: Pugs was written in Haskell initially. What was the advantage of re-writing it in Perl6 ?
FG: Only a few Perl6 developers were able to maintain the Haskell code base. We decided moving to Perl6 would make it easier to go ahead and we could keep the (Pugs) Haskell backend, which is nice for experimenting with technologies that Haskell supports - transactional memory, GPU programming, alternate parser algorithms.
NV: What happened to the Perlito Haskell backend ?
FG: Audrey added Haskell support to Pugs::Compiler::Rule, so that it could be used as a Haskell library, but the pure-Haskell Perlito backend never happened. Instead, we started exploring alternative backends.
NV: So how does the bootstraping process work? You start with a limited prototype and then build upon it incrementally?
FG: That is how it starts, yes - the initial implementation was a couple hundred lines of code, and at first was just compiled by hand.
NV: Can you provide a short high level overview of Perlito's underlying architecture or how does it work behind the scenes?
FG: Perlito has 2 compilers - a Perl6 compiler written in Perl6, and a Perl5 compiler written in Perl5
This is an old picture, but this is still pretty much how the Perlito compilers work:
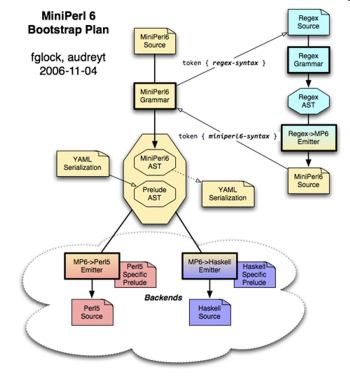
(click to enlarge)
There is a grammar, which transforms the input text into a data tree (AST), and there is an emitter, which transforms the tree into machine-readable code. Other modules are provided to handle other more complex cases.
In Perlito5, the grammar is implemented as Perl5 modules which you an see here:
http://github.com/fglock/Perlito/tree/master/src5/lib/Perlito5/Grammar
The internal structure of Perlito6 is more "monolithic", it needs some refactoring. There is a third component, which is the Runtime.This is where the backend-specific features (and workarounds) are implemented - for example, the CORE module for javascript:
https://github.com/fglock/Perlito/blob/master/src5/lib/Perlito5/Javascript2/CORE.pm
NV: Perlito's definition is : "a compiler collection that implements a subset of Perl5 and Perl6 ". Why a subset, what is left out and what cannot be done in comparison to the full-set?
FG: The plan is to support the full language, but this is not possible yet. Each backend supports a set of features; for example this file is a description for Perl5-in-Javascript.
Javascript does not support sleep(), for example. On virtual machines that do automated garbage collection, reference counting is hard and it is important to support DESTROY and automatic closing of file handles. You can work around in most cases, but there is usually an impact on performance
There are several steps in the compilation. Perlito parses the code, and then emits code that will be executed by a specific virtual machine. In some cases, there is no easy way to generate specific instructions, it is a limitation of the backend
I'm currently working on the x64 backend, this is very low level and should have fewer or no limitations.
NV: So Perlito can parse a full source script but when generating code for the backend it removes functionality because of the VM limitations?
FG: Yes - backends either remove functionality, or they emulate it. The parser has some problems, but these are not intentional - the parser limitations are bugs.
|