| Patently Ridiculous - Google Ordered To Pay $20 Million Plus |
| Written by Mike James | |||
| Monday, 20 February 2017 | |||
|
Software patents are usually patents on the obvious wrapped up in as obscure, vague and technical a language as possible. In this case Google has been found guilty of infringing a "sandbox" patent in Chrome. This story started five years ago when the owners of the patent filed a patent infringement lawsuit against Google claiming that Chrome's sandbox architecture was using ideas invented by them. Google won the first case in 2013, but then lost the appeal in 2015. It then tried to get the Supreme Court to hear the case but without any luck. The case was referred to a jury trial and the verdict was announced last week. The jury ruled that Google had infringed the patents and recommended a fine of $20 million as a running royalty. This means that Google has to keep paying while Chrome keeps infringing the patents. Some news headlines have reported this as "Google fined for ripping off patent", which I suppose is a litteral interpretation of the facts, but if you take a look at the patents in question things are not so clear cut.
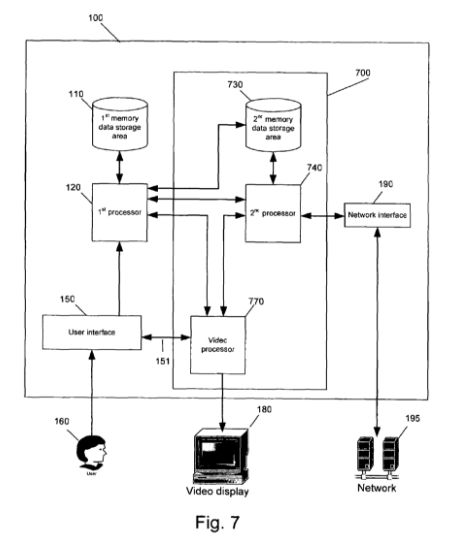
The main claim of the patent is: A method of operating a computer system capable of exchanging data across a network of one or more computers and having at least a first and second electronic data processor capable of executing instructions using a common operating system... The patent then goes on to describe almost any modern multicore computer architecture in incredibly vague terms. Basically the idea is that there are two processes or processors, only one having access to the network and there being some sort of barrier between the two. The grounds for infringement are that just such a scheme is supposed to be the architecture of Chrome, with the rendering engine and the browser core working together with the core accessing the network. There is some evidence that the patent was rewritten to specifically target browsers, although its broader claims are in no way browser-specific: ...executing instructions a second web browser process in a second logical process within the common operating system using the second electronic data processor, wherein the second logical process is capable of accessing data contained in the second memory space, the second logical process being further capable of exchanging data across a network of one or more computers; and displaying, in a windowed format on a display terminal, data from the first logical process and the second logical process, wherein a video processor is adapted to combine data from the first and second logical processes and transmit the combined data to the a display terminal;
Reading Google's complaint to the Supreme Court reveals what you might suspect - that the patent has been tailored to prove that Chrome infringes it. Google suggests that, after trying to get the patent accepted, a prior patent covering the same ground was found by the patentees and the patent's scope was narrowed to make it apply specifically to web browser processes. The problem is that the patent doesn't make clear what a web browser process is. You could say that the patent fails to make anything clear. You can even claim that its description of a second processor and separate memory area lets Chrome of the hook because that part of the architecture is incidental - it comes courtesy of Intel or ARM. In other words, Chrome's sandbox, if that's what you want to call it, isn't dependent on two processors, just an isolation between processes. But unfortunately no such argument was successful in the court hearing. You might say, so what - Google can afford it. This might be true, but $20 million from a browser that is given away and is mostly open source is a rich return. In addition if Chrome infringes the patent so do other browsers and, if you read the patent in its broadest context, so do most modern processors and programs. How can you be sure that you are not next in line to be sued? To quote Alex Amstrong back in 2012: When it comes to patent wars the only likely winners are the lawyers.
More InformationSystem and method for protecting a computer system from malicious software Federal Circuit Rules Against Google In Patent Litigation Related ArticlesBig Increase in AI, Cognitive and Cloud Computing Patents in 2016 Microsoft Enforcing Slider Patent Supreme Court Refuses To Reconsider API Copyright Decision White House Advises That APIs ARE Copyrightable Fujifilm Has A Patent On Converting To Greyscale Google's Open Patent Non-Assertion Pledge
To be informed about new articles on I Programmer, sign up for our weekly newsletter, subscribe to the RSS feed and follow us on Twitter, Facebook or Linkedin.

Comments
or email your comment to: comments@i-programmer.info |
|||
| Last Updated ( Monday, 20 February 2017 ) |