| Oracle's NoSQL 2.0 Released |
| Written by Kay Ewbank | |||
| Wednesday, 19 December 2012 | |||
|
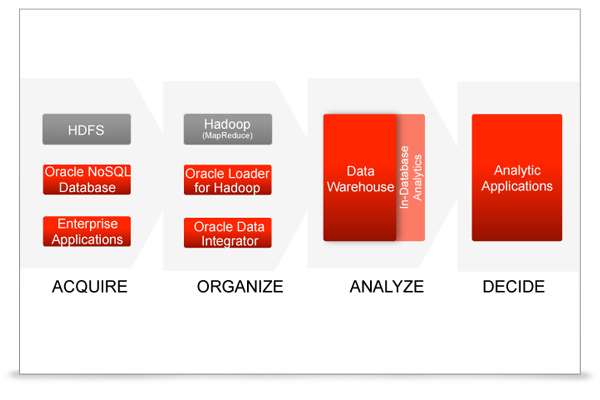
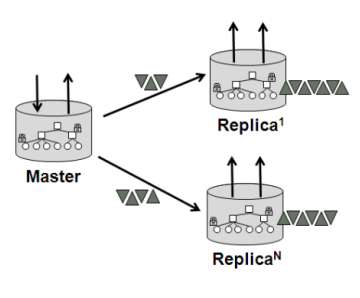
Oracle has released 2.0 of NoSQL, with better integration with Hadoop and Oracle Database. A new version of Oracle NoSQL has been released following its launch in September 2011. Oracle has based its NoSQL on the Oracle Berkeley DB key value store with flexible transaction support, and says the new NoSQL is a key part of its Big Data platform. Oracle NoSQL is described by Oracle as a highly scalable, low latency, key-value database for real-time big data workloads. The new version improves support for storage and retrieval of large objects such as documents and images, as well as automatic rebalancing for allocating storage and compute resources. It also offers tighter integration with both Oracle Database and Hadoop environments.
The performance of the new version is claimed to offer near linear scalability and under five millisecond latency. Oracle says that in recent performance tests, Oracle NoSQL Database 2.0 delivered more than a million YCSB (Yahoo Cloud Serving Benchmark) operations per second on a 2.4 terabyte database on an 18-node commodity cluster setup. New APIs have been added in addition to the basic APIs from version 1. There’s a new C API along with a new Large Object API and new automatic serialization APIs. The C interface uses the Java Native Interface (JNI) to access the Java client interface and therefore requires a JVM on the C client as well. Both it and the Java APIs provide basic Create, Read, Update and Delete (CRUD) operations and a collection of iterators are packaged in a single jar file. Applications can use the APIs from one or more client processes that access a stand-alone Oracle NoSQL Database server process. The libraries also include Avro support, so that developers can serialize key-value records and de- serialize key-value records interchangeably between C and Java applications.
The tighter Integration with Oracle Database means Oracle Database users can view and query Oracle NoSQL Database records directly from SQL via External Tables, while the Hadoop integration is achieved through JSON object and schema evolution support for data storage and serialization using Apache Avro. NoSQL Database OrientDB 1.0 Released
To be informed about new articles on I Programmer, install the I Programmer Toolbar, subscribe to the RSS feed, follow us on, Twitter, Facebook, Google+ or Linkedin, or sign up for our weekly newsletter.
Comments
or email your comment to: comments@i-programmer.info

|
|||
| Last Updated ( Wednesday, 19 December 2012 ) |