| Apache Spark 2.0 Released |
| Written by Kay Ewbank | |||
| Friday, 29 July 2016 | |||
|
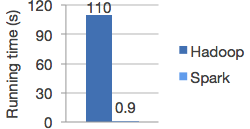
Apache Spark 2.0 has been released with updated SQL support, structured streaming and better performance. Apache Spark is an open source data processing engine that has become very popular since its initial release. It improves on Hadoop MapReduce performance, running programs up to 100 times faster in memory and ten times faster on disk, according to Apache. The graph below shows logistic regression in Hadoop and Spark (according to Apache).
The new version has improved support for standard SQL, with a new ANSI SQL parser and support for subqueries. The parser supports both ANSI-SQL and Hive QL, while the subquery support covers uncorrelated and correlated scalar subqueries; NOT IN predicate subqueries; IN predicate subqueries; and (NOT) EXISTS predicate subqueries. The support for SQL:2003 means Spark 2.0 can run all the 99 TPC-DS queries, and more generally will make it much easier to port apps that use SQL to Spark. Spark is guaranteeing stability of its non-experimental APIs for this (and all 2.X) releases. There has been extensive work on the APIs, with DataFrames and Datasets being unified in Scala and Java. In Python and R, given the lack of type safety, DataFrame is the main programming interface. The SparkSession API has also been reworked, and has a new entry point that replaces SQLContext and HiveContext. The Accumulator API has also been redesigned with a simpler type hierarchy and support specialization for primitive types. In the area of machine learning, the developers say that a spark.ml package, with its “pipeline” APIs, will become the primary machine learning API, and the focus for future development will be the DataFrame-based API. Pipeline persistence has also been added, so users can save and load machine learning pipelines and models across all programming languages supported by Spark. MLlib is Spark's scalable machine learning library. It fits into Spark's APIs and interoperates with NumPy in Python (starting in Spark 0.9). You can use any Hadoop data source (e.g. HDFS, HBase, or local files), making it easy to plug into Hadoop workflows. The largest improvement to SparkR in this version is support for user-defined functions. According to the release notes, there are three user-defined functions: dapply, gapply, and lapply. The first two can be used to do partition-based UDFs using dapply and gapply, e.g. partitioned model learning. The latter can be used to do hyper-parameter tuning. Other enhancements to R support add the ability to use Generalized Linear Models (GLM), Naive Bayes, Survival Regression, and K-Means in R. A Structured Streaming API has been added that is built on top of Spark SQL and the Catalyst optimizer. This means you can program against streaming sources and sinks using the same DataFrame/Dataset API as in static data sources. This will make use of the Catalyst optimizer to automatically incrementalize the query plans. The new version is available either from Apache Spark or on Databricks, where the Databricks team has been contributing to Spark over recent months.
More InformationRelated ArticlesApache Spark Technical Preview
To be informed about new articles on I Programmer, sign up for our weekly newsletter,subscribe to the RSS feed and follow us on, Twitter, Facebook, Google+ or Linkedin.

Comments
or email your comment to: comments@i-programmer.info |
|||
| Last Updated ( Friday, 29 July 2016 ) |