| Cracking a Skype call using phonemes |
| Written by Mike James | |||
| Thursday, 26 May 2011 | |||
|
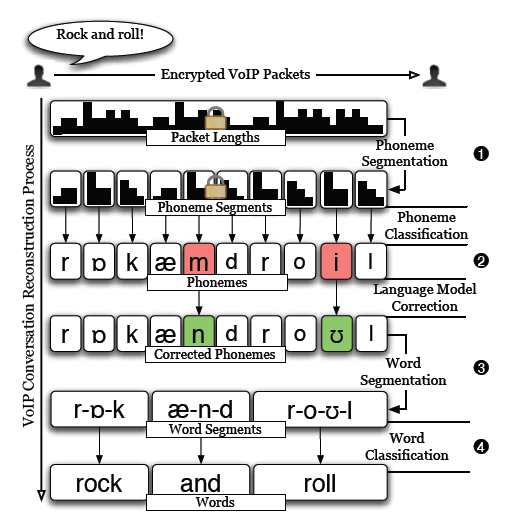
Modern computational linguistics can crack the encryption on VOIP calls well enough to reconstruct what is being said. Even though they are encrypted, the frames that make up a Skype call contain clues about what phonemes are being spoken. Cracking a code is usually a complex matter of mathematics and nothing much else other than mathematics. However, if the encrypted data contain any statistical relationship to the original data then there can be shortcut ways to decryption that make the whole thing much less secure. This is well known and yet you might be surprised to discover that Skype, and many other forms of VOIP telephone systems, are vulnerable to this sort of attack. The reason is that the best form of compression for voice data makes use of the structure of speech - the Linear Predictive Filter. The basic idea is that the data is compressed by using an input code word that represents the sound made in the throat by the vocal chords. Then a set of parameters are set in a filter which represents the shape of the mouth and resonant cavities. The parameters are set so that the output matches the sound as well as it can - this is an example of analysis by synthesis, i.e. you analyze a signal by setting up a system that creates it accurately. Skype uses Code Excited Linear Prediction in which the data in a frame consists of a code word, the gain coefficient and a set of linear prediction coefficients. The next step in processing the data is that the frame is compressed using a variable bit rate scheme and this produces a frame that has a size that does depend on the type of phoneme that has been encoded. The encryption step that follows doesn't change the size of the frame and so the encrypted data that is transmitted has a correlation between frame size and phoneme uttered. In theory working out what is said from a loose correlation between frame size and phoneme should be very difficult. However a computer scientists and linguists at the University of North Carolina have used the grammar of phonemes to restrict the possibilities for pairs and larger groups of phonemes in the data stream. This allows them to match the patterns of data frame sizes with most likely patterns of phonemes. These phoneme patterns are then mapped to most likely words, a technique they call "Phonotactic Reconstruction".
In practice it turned out to be surprisingly effective - although probably not good enough to eavesdrop on any conversation at any time. Some times the method works much better than expected and some times it can't crack the data stream. The researchers state that with improved computational linguistics they could achieve a much better success rate. What ever the future holds it is clear that the method of compression leaves too much information in the clear after encryption. A solution might be to break the data up into fixed sized frames but this would make it more difficult to reconstruct the data if there was packet loss. More informationPhonotactic Reconstruction of Encrypted VoIP Conversations
If you would like to be informed about new articles on I Programmer you can either follow us on Twitter or Facebook or you can subscribe to our weekly newsletter.

|
|||
| Last Updated ( Thursday, 26 May 2011 ) |