
| An Exponential Law For AI Compute |
| Written by Sue Gee | |||
| Wednesday, 23 May 2018 | |||
|
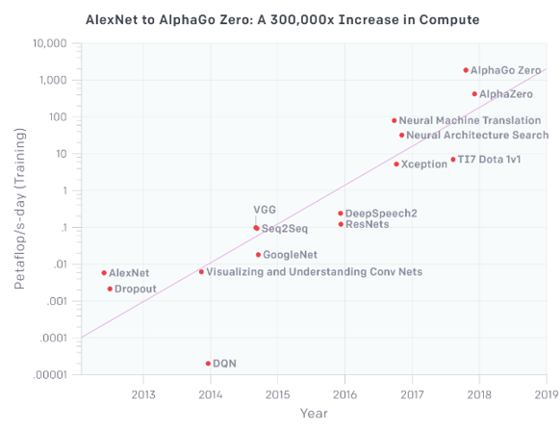
OpenAI has released an analysis showing that since 2012, the amount of compute used in the largest AI training runs has has grown by more than 300,000x. To put it another way, the computer resources used in AI has doubled every 100 days.
(click in graph to enlarge)
We are all familiar with Moore's Law - that the number of transistors per unit area on a chip doubles every year, an observation made in 1965 by co-founder of Intel, Gordon Moore. Now Dario Amodei and Danny Hernandez have made a similar observation with regard to the increase in the amount of compute, in petaflop seconds per day, devoted to training neural networks. To quote from their blog post explaining their findings: The chart shows the total amount of compute, in petaflop/s-days, that was used to train selected results that are relatively well known, used a lot of compute for their time, and gave enough information to estimate the compute used. A petaflop/s-day (pfs-day) consists of performing 1015neural net operations per second for one day, or a total of about 1020operations. The compute-time product serves as a mental convenience, similar to kW-hr for energy. We don’t measure peak theoretical FLOPS of the hardware but instead try to estimate the number of actual operations performed. We count adds and multiplies as separate operations, we count any add or multiply as a single operation regardless of numerical precision (making “FLOP” a slight misnomer). Amodei and Hernandez explain how they generated the data points in the chart in an Appendix. The preferred methodology was to directly count the number of FLOPs (adds and multiplies) in the described architecture per training example and multiply by the total number of forward and backward passes during training. When there was insufficient information to directly count FLOPs, they looked at GPU training time and total number of GPUs used and assumed a utilization efficiency (usually 0.33). For the majority of the papers they were able to use the first method, but for a significant minority they relied on the second. They also computed both whenever possible as a consistency check. The appendix provides examples of both methods and links to many of the papers used. Outlining the reasons motivating this analysis, Amodei and Hernandez argue that three factors drive the advance of AI: algorithmic innovation, data (which can be either supervised data or interactive environments), and the amount of compute available for training. While algorithmic innovation and data are difficult to track, they state that compute is "unusually quantifiable" and therefore provides an opportunity to measure an input to AI progress. For this analysis, they chose to measure the amount of compute that is used to train a single model as being: "the number most likely to correlate to how powerful our best models are." As demonstrated in the chart above which has a log scale on the y-axis, the trend represents an increase by roughly a factor of 10 each year. The researchers comment that the increase has been driven partly by custom hardware that allows more operations to be performed per second for a given price (GPUs and TPUs), but it’s been primarily propelled by researchers repeatedly finding ways to use more chips in parallel and being willing to pay the economic cost of doing so. They note that: AlphaGoZero/AlphaZero is the most visible public example of massive algorithmic parallelism, but many other applications at this scale are now algorithmically possible, and may already be happening in a production context. They point to four distinct eras revealed by the chart:
Moore's Law turned out to be valid decades into the future and the two researchers believe the trend they have demonstrated might have similar predictive power writing: Improvements in compute have been a key component of AI progress, so as long as this trend continues, it’s worth preparing for the implications of systems far outside today’s capabilities. More InformationRelated Articles
|

Linux Foundation Launches Agent2Agent Project 24/06/2025 The Linux Foundation has launched the Agent2Agent (A2A) project, an open protocol created by Google for secure agent-to-agent communication and collaboration. |
Google Introduces Gemini CLI Open-Source Agent 08/07/2025 Google is introducing Gemini CLI, an open-source AI agent that offers lightweight access to Gemini, Google's conversational chatbot that is based on Google's multimodal large language model [ ... ] |
More News
|

Comments
or email your comment to: comments@i-programmer.info