| AlphaGo Zero - From Nought To Top In 40 Days |
| Written by Sue Gee | |||
| Thursday, 19 October 2017 | |||
|
DeepMind has revealed details of latest evolution of the computer program that plays the ancient Chinese board game of black and white stones. Unlike previous versions. which were trained with data from human games, AlphaGo Zero started with no prior knowledge and learned simply by playing itself.
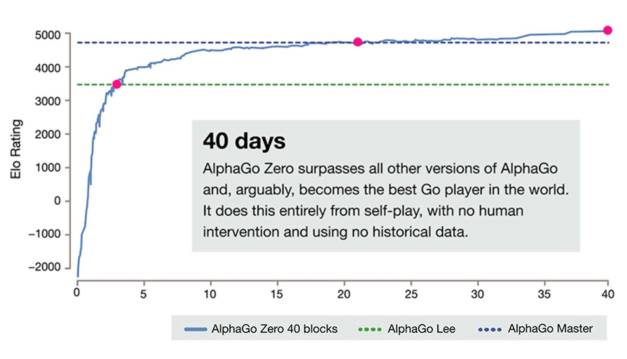
AlphaGo Zero's progress was rapid. After just three days of self-play it surpassed the abilities of version of AlphGo that defeated 18-time world champion Lee Sedol in March 2015. After three weeks it reached the level of AlphaGo Master, the version that, as a mystery player, defeated 60 professionals online at the beginning of 2017 and then beat world champion Ke Jie 3-0 in May 2017. After 40 days it reached the final milestone in this chart at which point it was able to beat all other versions of AlphaGo and hence the Go player with the highest Elo rating.
In this video David Silver, the lead researcher on DeepMind's AlphaGo team explains how the programs success was achieved by starting with absolutely no idea of how to play the game and learning from scratch, always playing a perfectly matched opponent- itself - and developing more principled algorithms as a result:
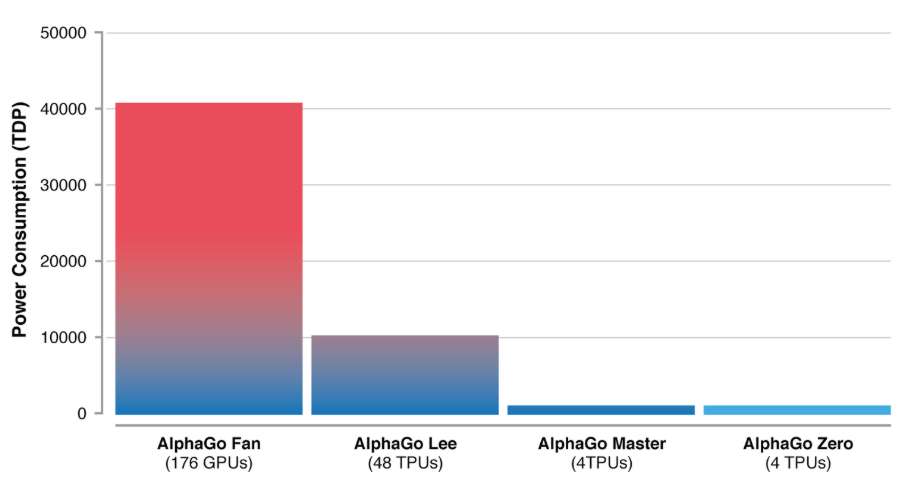
The idea that AlphaGo Zero is its own teacher that starts with a neural network that knows nothing about the game of Go is its novel feature. It proceeds using reinforcement learning and by combining its neural network with a powerful search algorithm. As it plays, the neural network is tuned and updated and the updated neural network is then recombined with the search algorithm to create a new, stronger version. At each iteration, the performance of the system improves by a small amount, and the quality of the self-play games increases, leading to more and more accurate neural networks and ever stronger versions of AlphaGo Zero. According to the DeepMind blog post: This technique is more powerful than previous versions of AlphaGo because it is no longer constrained by the limits of human knowledge. Instead, it is able to learn tabula rasa from the strongest player in the world: AlphaGo itself. The system is also more efficient than previous versions:
As we have previously reported, AlphaGo's career as a Go player has ended. As David Silver says at the end of this video, having shown how much it can can achieve in a domain as complex as Go it is time for its prowess can now be applied in the real world to address the most challenging and impactful problems faced by humanity.
A similar idea is expressed in the paper authored by David Silver and a large number of co-author's including Demis Hassabis that has been published in the journal Nature: Go is exemplary in many ways of the difficulties faced by artificial intelligence: a challenging decision-making task, an intractable search space, and an optimal solution so complex it appears infeasible to directly approximate using a policy or value function. The previous major breakthrough in computer Go, the introduction of MCTS (Monte Carlo Tree Search), led to corresponding advances in many other domains; for example, general game-playing, classical planning, partially observed planning, scheduling, and constraint satisfaction. By combining tree search with policy and value networks, AlphaGo has finally reached a professional level in Go, providing hope that human-level performance can now be achieved in other seemingly intractable artificial intelligence domains.
More InformationAlphaGo Zero Learning From Scratch Related ArticlesAlphGo Defeats World's Top Ranking Go Player AlphaGo To Play World Number One Go Player World Champion Go Player Challenges AlphaGo AlphaGo Revealed As Mystery Player On Winning Streak Why AlphaGo Changes Everything AlphaGo The Movie - Who Is The Hero? Competitive Self-Play Trains AI Well
To be informed about new articles on I Programmer, sign up for our weekly newsletter, subscribe to the RSS feed and follow us on Twitter, Facebook or Linkedin. 
Comments
or email your comment to: comments@i-programmer.info
|
|||
| Last Updated ( Thursday, 19 October 2017 ) |